
In my previous blog, I showed you how to integrate Stanford CoreNLP with Talend using a simple example. In this post I’ll show you how to modify that code in order to make the most of Talend’s strengths as a data integration tool.
Let’s get to it
Below is a Talend job I have built to read some tweets from a database (see this blog article for information on how to retrieve tweets with Talend), run the text through the CoreNLP sentiment analysis code, and then write tweets back to the database with the addition of the sentiment.
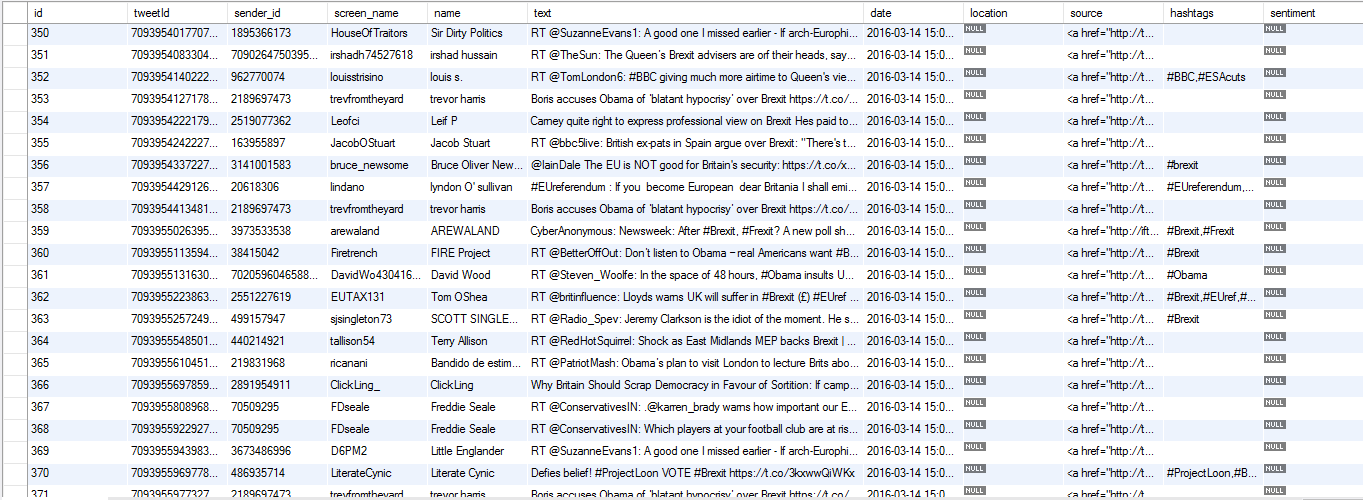
In this particular example, the text to be analysed are tweets coming from a database. However, the same job will work with any string input. Below is a screenshot of the database table to be processed (note the sentiment column on the end which is blank for all rows).
Prejob & Library Loads
I explain how to set up the pre-job sequence in my previous post.
tMysqlinput_1
This component reads all the rows from a MySQL table that contains tweets I have retrieved from the Twitter streaming API. However it is not important where the data has come from, just that you supply the next component in the job (tjavaRow_1) with a string field that it can do sentiment analysis on. In this example I will be performing sentiment analysis on the text field from my DB table.
tJavaFlex_1
The tJavaFlex has the below code in it.
Start Code:
Properties props = new Properties();
props.setProperty(“annotators”, “tokenize, ssplit, pos, lemma, parse, sentiment”);
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
Main Code:

The above code splits the text into its subsequent sentences, runs the CoreNLP sentiment analyser on each sentence and scores the sentence from +2 to -2 based on whether the analysis comes back with “Very Positive”, “Positive”, “Neutral”, “Negative” or “Very Negative” respectively. The sum of the scores is output to the sentiment_score field as you can see at the bottom of the code.
tMap_1
There is not much going on in the tmap, other than the following logic, to work out the sentiment based on the sentiment score which was calculated in the last step.
![]()
tMysql_Ouput_1
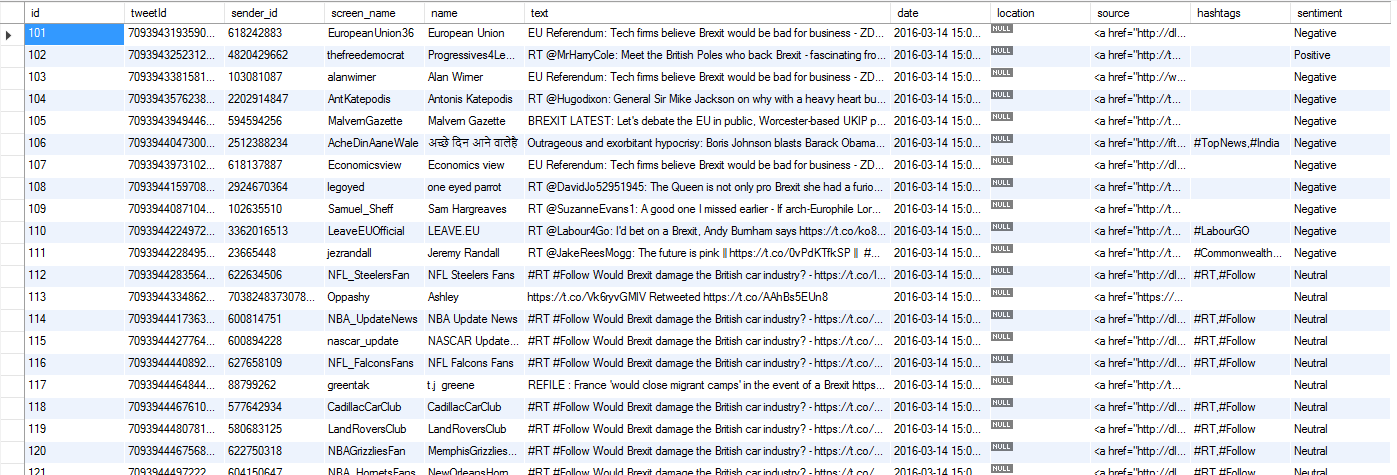
This component writes the rows back to the table with a sentiment value now populated in the sentiment field.
Conclusion
I hope you have found this post useful or interesting and please feel free to leave comments and questions below. I suggest subscribing to our blog page in order to keep up to date with the latest articles.
0 Comments