
Talend Cloud users typically run tasks in Talend Cloud every day and night. However, a common issue that users see is that an important Talend Management Console (TMC) task hangs overnight, heavily impacting the daily BAU processes that rely on it.
TMC currently does not include a function to automatically time out, kill or restart jobs.
Solution
Here at Mphasis Datalytyx, we’ve built a process that is automatically set up to look at all tasks that have been set up on the TMC and take a snapshot of their current execution status, whether
- idle,
- running on time,
- or running over a set time threshold;
the latter suggesting they are in a “hanged” state and need to be terminated and, if required, restarted.
The process has been built to be as generic as possible to allow for easy deployment for any client, requiring only a few necessary contextual input parameters to be set up (including TMC region, environmentId, and workspaceId).
Once deployed, the process kills/terminates any execution that is running longer than 75% of its scheduled time (i.e., if run every 10 minutes, terminate the task after 7.5 minutes). This value is configurable as well, and can be overridden with set values, based on internal requirements for each task (i.e., for example, if run once daily at midnight, with an average completion time of 2 hours, kill it and restart it if it goes over 2½ hours). It can also be further configured to assist with better plan executions, where tasks are dependent on previous tasks to be started.
This process requires no changes to existing jobs – the process only reads TMC task metadata running in the production environment; no client data is ever read. It can also be used for sending email or other alerts if certain conditions are met and can serve as a replacement or addition to monitoring tools like DataDog.
The main point is that once configured, it alleviates the tedious manual labour of checking the status of all jobs that have run overnight when first logging in to work every morning. It also saves time for this kind of recovery maintenance, reducing the impact on the business reporting team that previously would have had to wait for the maintenance team to fix/restart tasks that failed during out-of-office hours.
Following that, the automatic monitoring and killing/restarting the hanging jobs frees up the time of the developers and data engineers who would normally be called to investigate and restart the jobs. This saves the company money by ensuring less time is wasted maintaining jobs and more time of the budget is spent on improving the current jobs and building new processes.
The process can also be set up to store analytics about the task executions in Snowflake, and this information can be used to build reports on the TMC performance. Using the stored metadata about the task executions to build a status dashboard will show trends and stats related to the TMC performance and provide insights into where further improvements to the system can be made.
The chart below is an example mock-up of stats gathered by the process and stored in Snowflake.
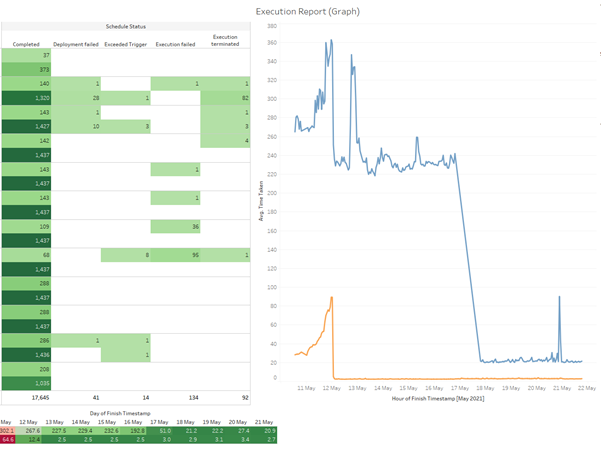
The chart on the left monitors the number of tasks and their statuses. After implementation of the TMC monitoring solution, the task durations, represented by the two rows (two tasks running) at the bottom are getting shorter.
The right chart monitors the task duration over time. The blue and the orange lines represent two separate tasks. After implementation the duration of each task was significantly reduced. This chart can show, at a glance, the time each task is taking compared to its normal duration so that a user can easily spot a problem and fix the issue.
Conclusion
This is an elegant solution to an issue we have seen across many different clients moving to the Cloud and TMC that will save time and money.
If you’re interested contact us for more information (info@datalytyx.com). We can publish this process to your Cloud.
This post was co-authored by Andreas Karlsson and Gio Pagliari of Mphasis Datalytyx.
0 Comments