What is ThoughtSpot?
ThoughtSpot is a new breed of search engine designed for data analytics. As you type, ThoughtSpot instantly calculates answers and presents the best visualization for your search. Anyone can use ThoughtSpot with zero training to ask questions, analyse company data, and build reports and dashboards – all in seconds. ThoughtSpot combines data from on-premises, cloud data sources, spreadsheets, and Hadoop. It can scale to billions of rows and be deployed in hours.
ThoughtSpot’s search engine uses collective intelligence to guide users to the right answers and is powered by a sophisticated calculation engine capable of performing aggregations over terabytes of data with sub-second latency. Complete with robust integration, fine-grained security rules, and cluster management for reliability and massive scalability, ThoughtSpot brings instant answers to every business professional.
Data load options
The way I think of ThoughtSpot is as an extension to your current data warehouse architecture, just as you would create data marts as the access layer for specific business areas. ThoughtSpot acts in the same way and can serve those different business areas and use cases.
So to create these ThoughtSpot data marts you need a method of loading the data and there are a number of options available to you. Here are a few…
Data Connect
ThoughtSpot Data Connect is a web interface for connecting to databases and applications to move data into ThoughtSpot. Essentially it is Informatica Cloud with a ThoughtSpot connector and probably doesn’t represent the most value for money option as it requires separate license cost.
ODBC / JDBC
ThoughtSpot provides an ODBC & JDBC (Open/Java Database Connectivity) driver to enable transferring data from your ETL tool into ThoughtSpot. This is probably the easiest way to integrate ThoughtSpot into your existing ETL processes, however it is not necessarily the most performant, we will come to that.
User Data Import
Users can upload a spreadsheet through the web interface with User Data Import. This is useful for giving everyone easy access to loading small amounts of their own data. This is useful for one-off / PoC type experiments but it’s not an operational approach to loading data into ThoughtSpot.
ThoughtSpot Loader (TSLoad)
ThoughtSpot Loader is a command line tool to load csv files into an existing database schema in ThoughtSpot. This is the fastest way to load extremely large amounts of data. And this is the method we will be using to load data with Talend in this article.
ODBC/JDBC vs TSLoad
Using the TSLoad method leverages multithreaded hashing which has been optimised for the ThoughtSpot MPP architecture. So when you load a csv, ThoughtSpot will split this file up and distribute that workload across the available resources which results in a huge performance increase when compared to using the ODBC/JDBC approach.
Setting up a TSLoad Joblet in Talend
Before you can load data into ThoughtSpot, you must build a database schema to receive it. We will do this by writing a SQL script, which creates the objects in your schema.
You can learn how to do this here.
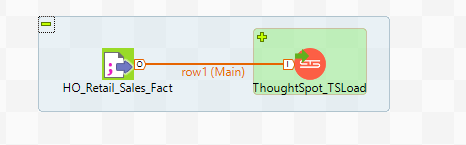
Once we have done the initial setup we can begin to create our ThoughtSpot joblet. A Joblet is a specific component that factorises recurrent processing so that it can be reusable across multiple jobs regardless of the type of input and output data source. Joblets are available in enterprise versions of Talend.
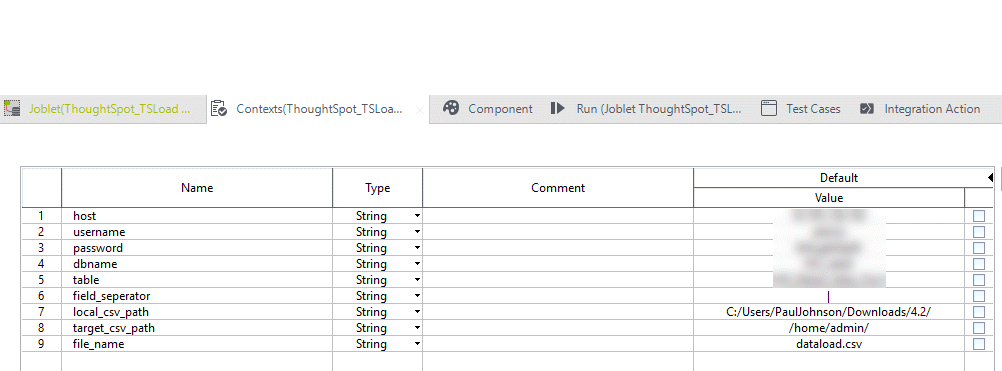
The first thing we should do is set up the context variables we need in the joblet shown in the screenshot below.
- Host
- Username
- Password
- Dbname
- Table
- Field_seperator
- Local_csv_path
- Target_csv_path
- File_name
Next select the components used in the joblet and drag them onto the canvas
- Joblet Input
- tFileOutputDelimited
- tFTPConnection
- tFTPPut
- tSSH
- tFTPDelete
- tFTPClose
You will connect the components by using the on component/subjob OK trigger.
To use the tsload command we need to have the csv file on the thoughtspot machine so we do that by transferring via SFTP.

The configuration of most of the components will hopefully be self-explanatory using the context variables we have already created with the exception of the tSSH component.
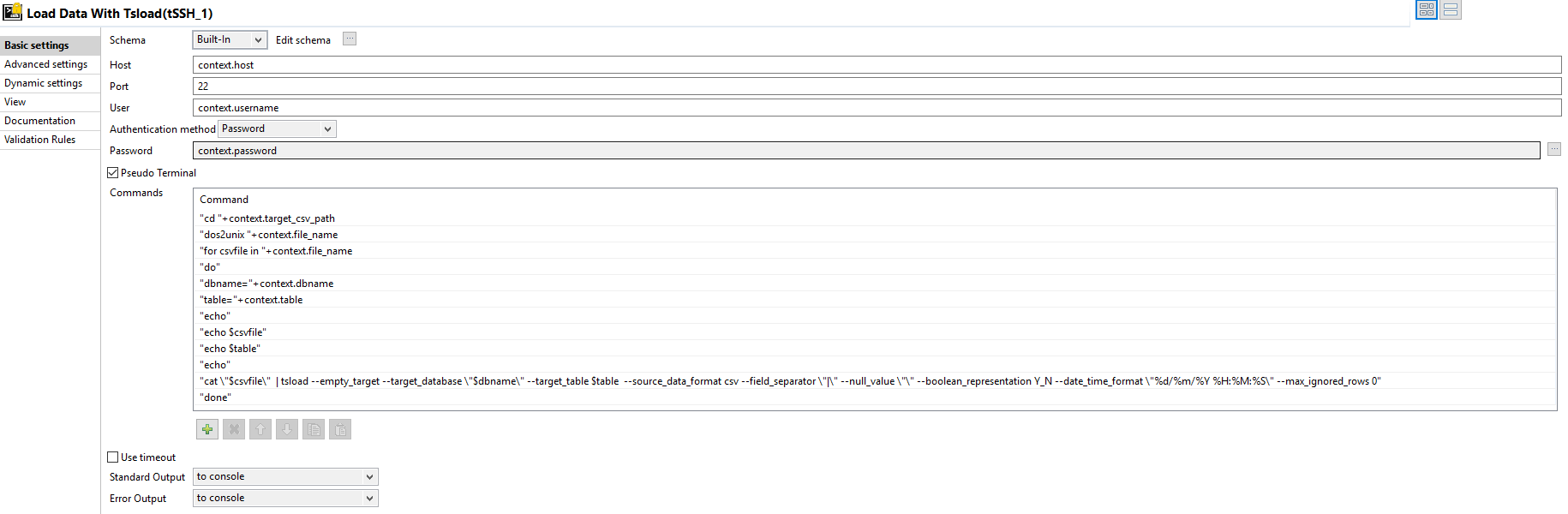
Select the Pseudo Terminal checkbox and add the following commands
“cd “+context.target_csv_path
“dos2unix “+context.file_name
“for csv file in “+context.file_name
“do”
“dbname=”+context.dbname
“table=”+context.table
“echo $csvfile”
“echo $table”
“cat \”$csvfile\” | tsload –empty_target –target_database \”$dbname\” –target_table $table –source_data_format csv –field_separator \”,\” –null_value \”\” –boolean_representation Y_N –date_time_format \”%d/%m/%Y %H:%M:%S\” –empty_target –max_ignored_rows 0”
“done”
The tsload command has optional flags which can used to modify the behaviour of tsload. A full list can be found here.
Save the Joblet and create a job for which to use it in.
In the example below my source data is a csv file but it could be any component that produces a data flow output.
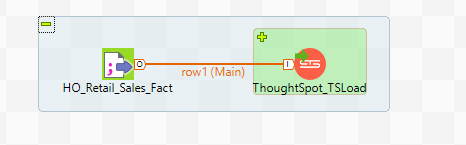
Once you have the joblet on the canvas you can expand it by clicking the + icon and on the tFileOutputDelimited component click the sync columns button on the component settings tab.
The job is now ready to run.
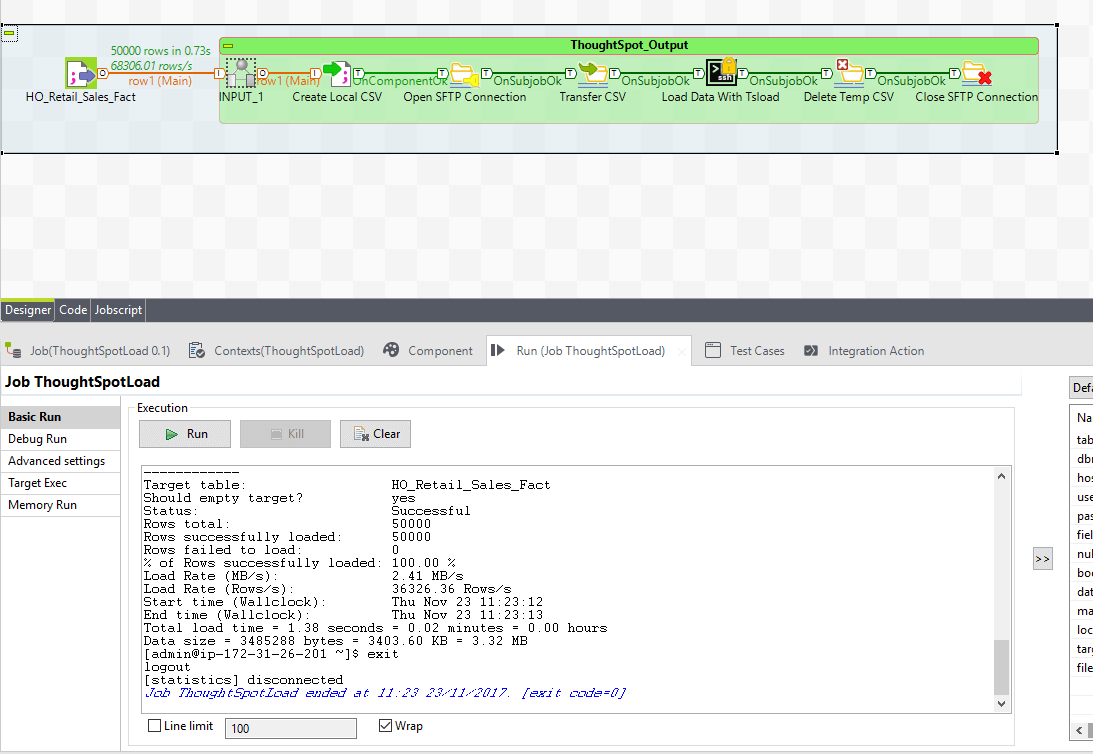
The console will display information about the tsload operation.
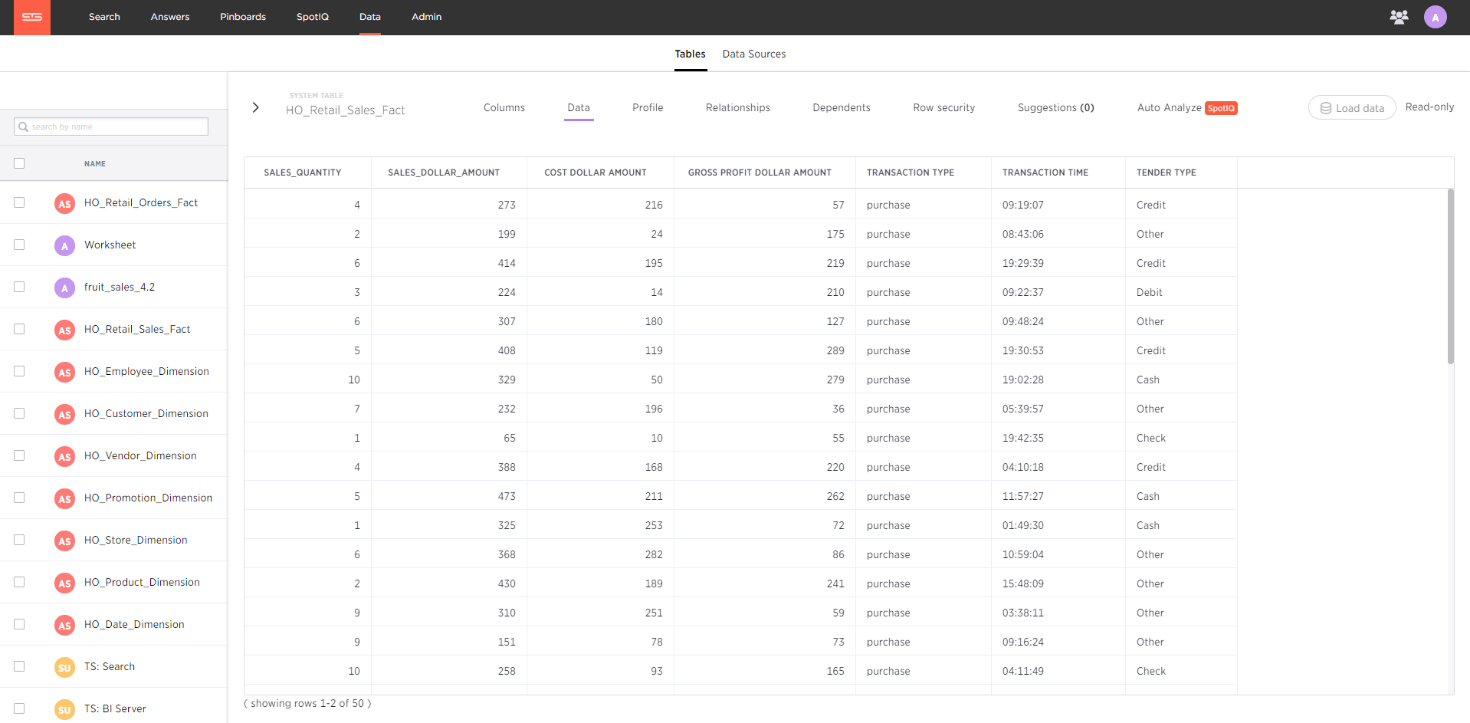
Once the job has completed we can quickly log into ThoughtSpot and see our data has appeared.
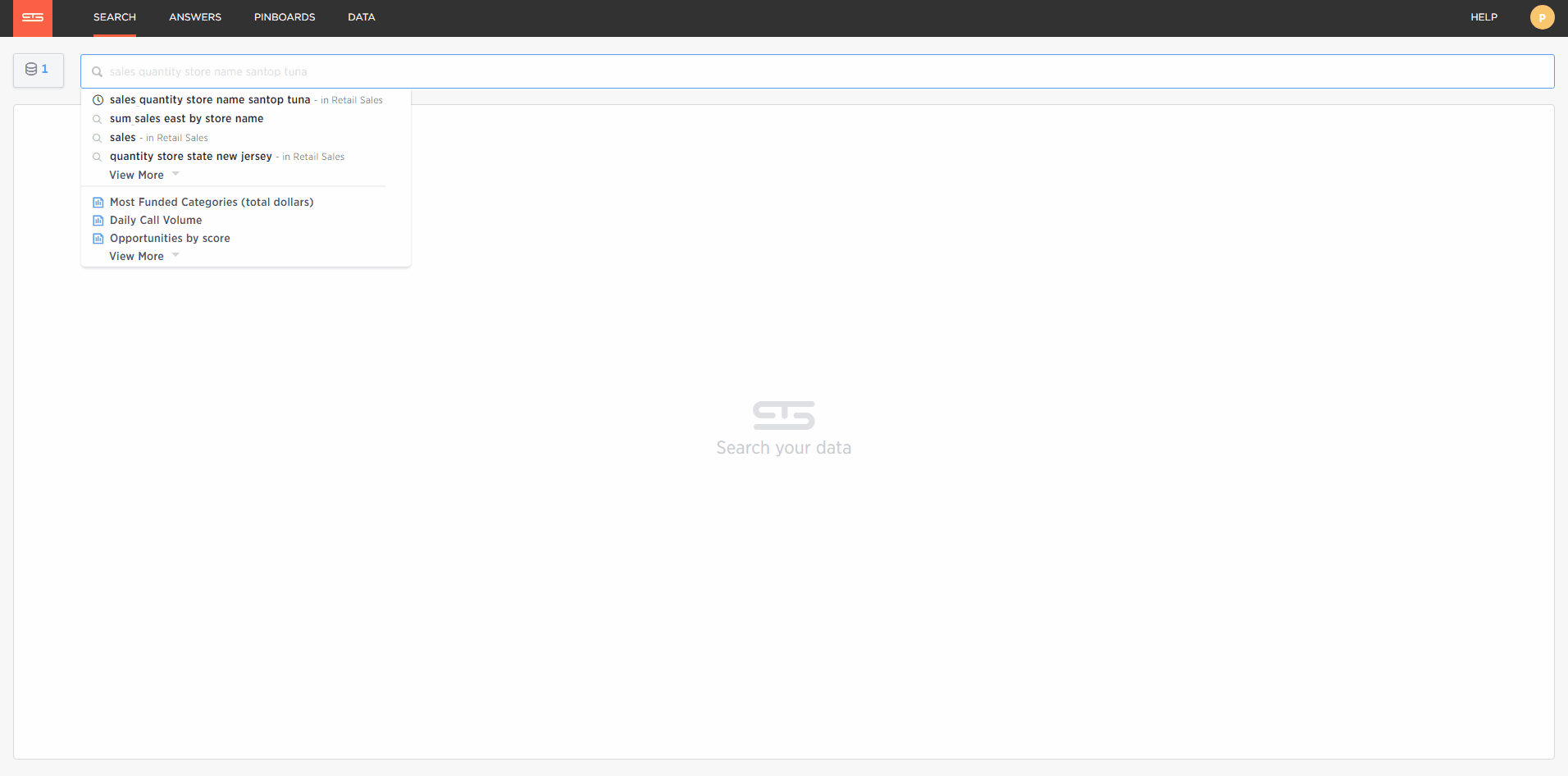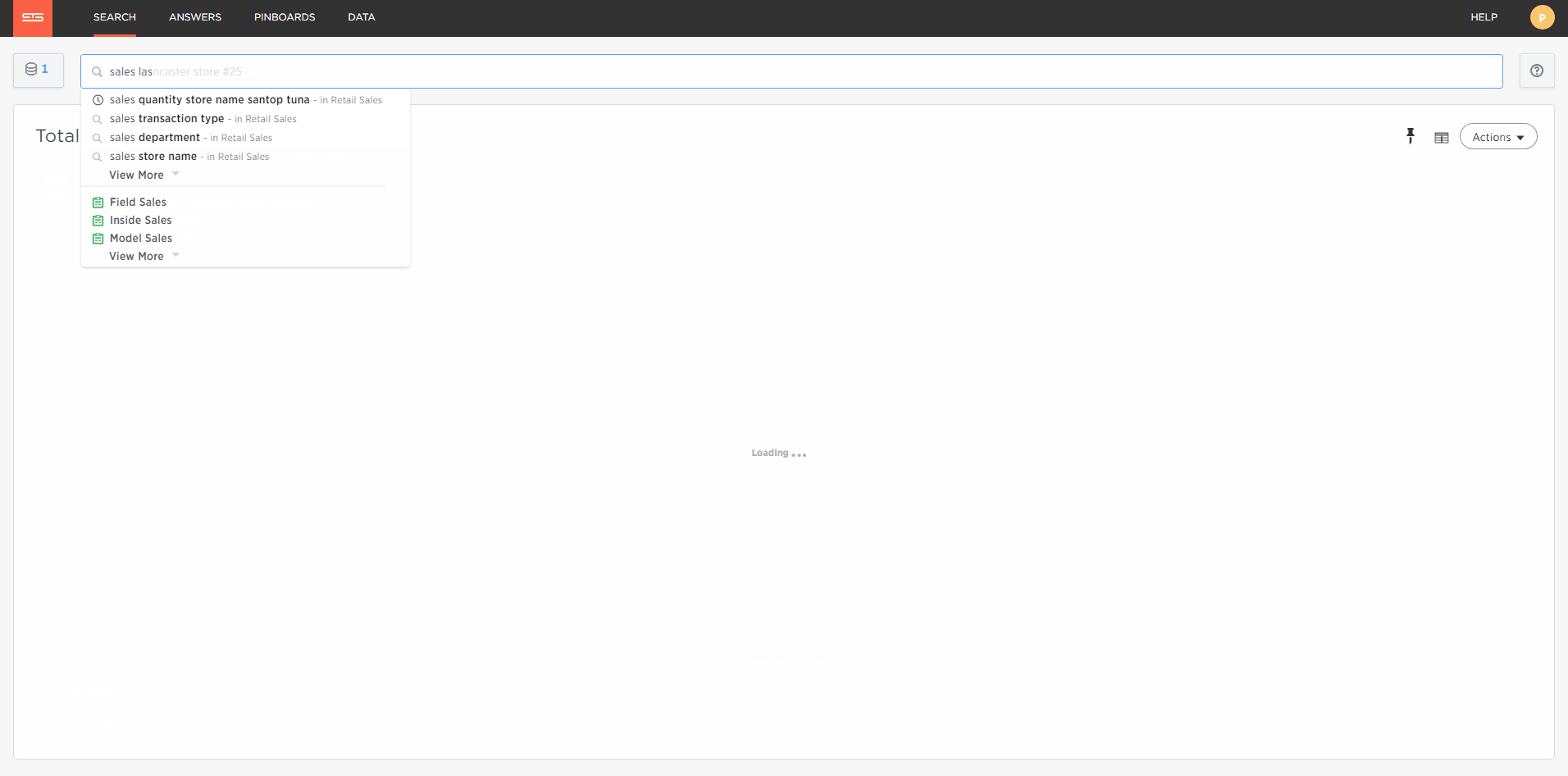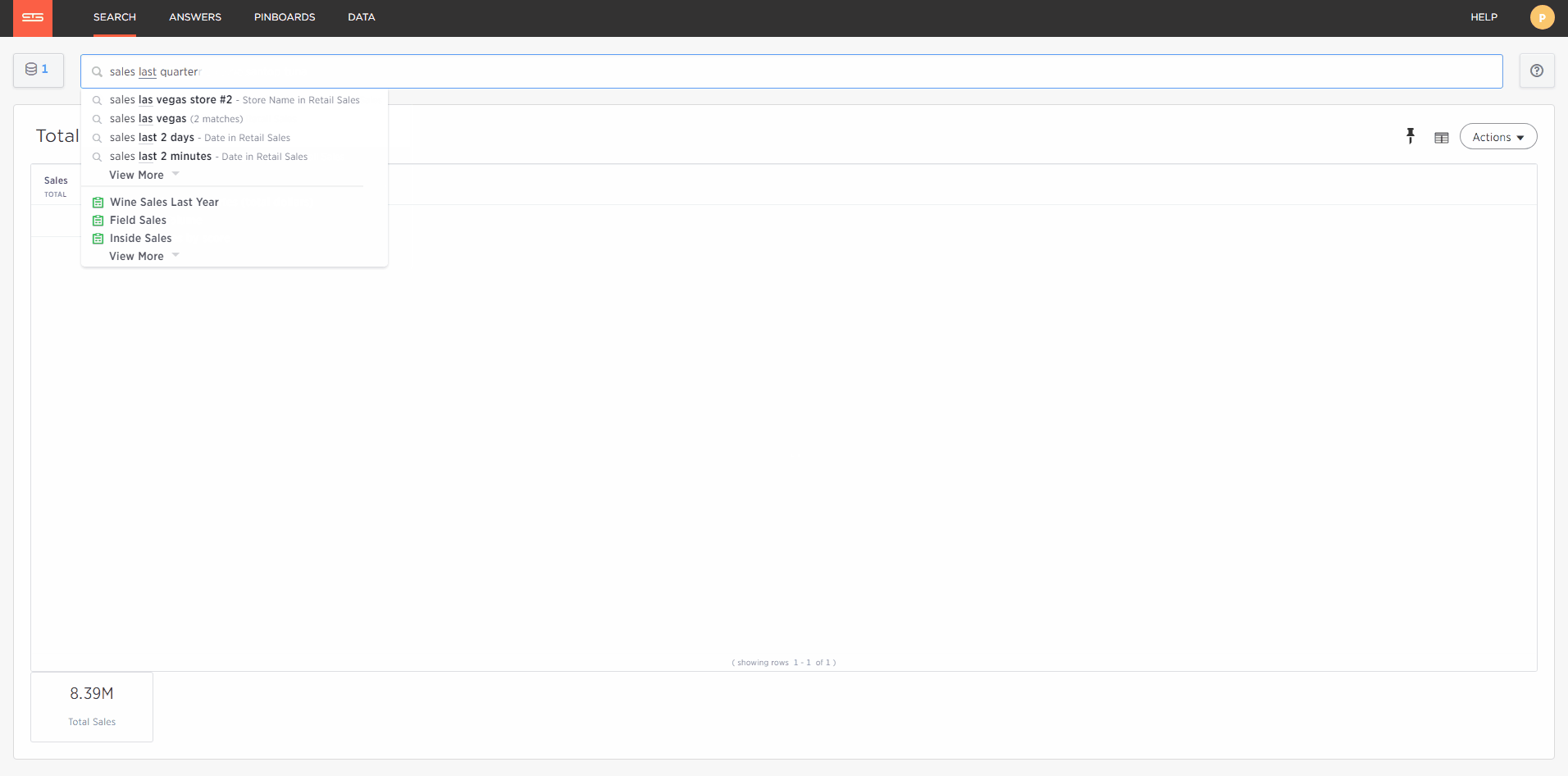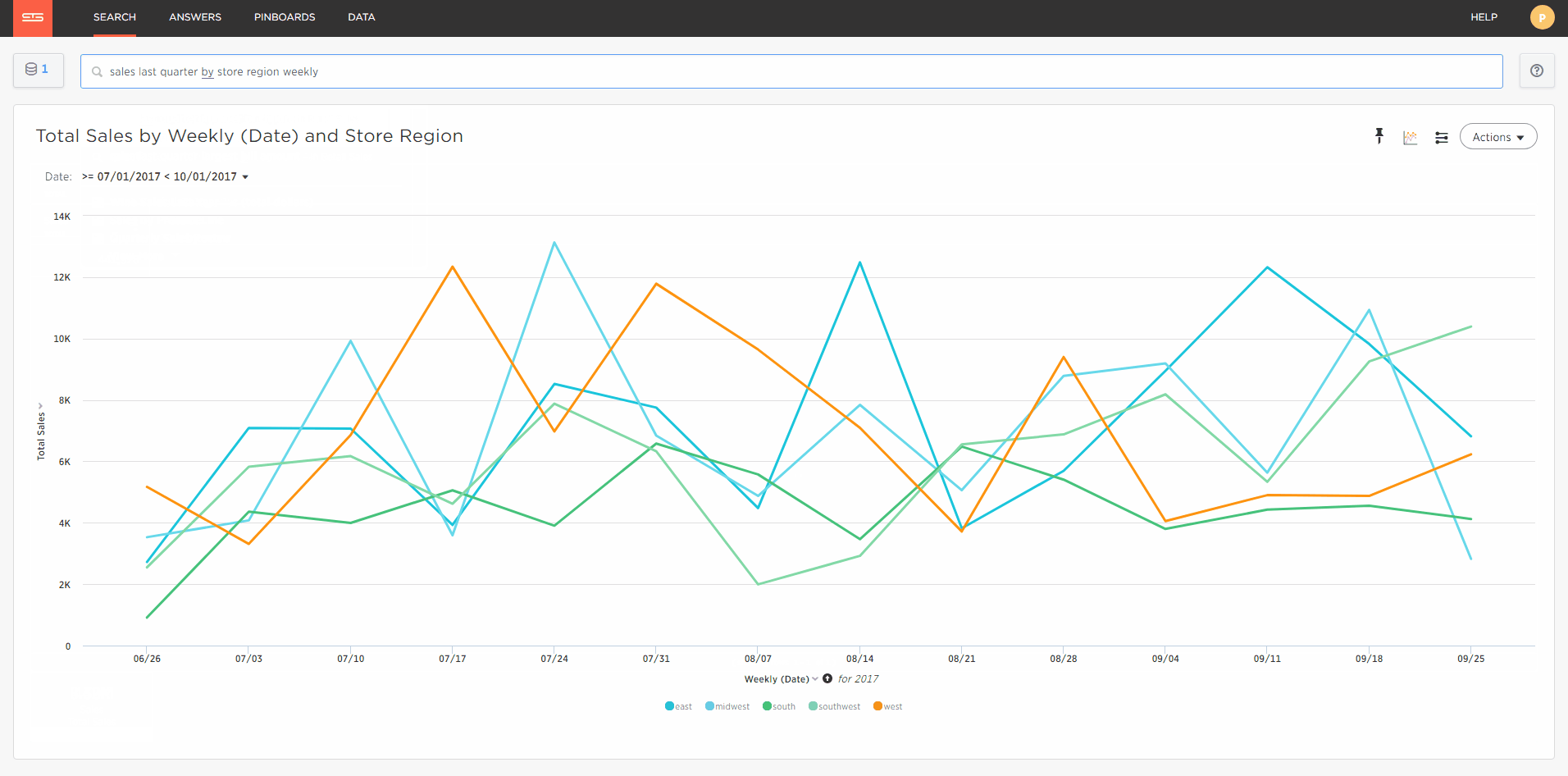
Now my data is loaded I simply click search and begin typing what I want to see, for example weekly sales in the last quarter by store region.
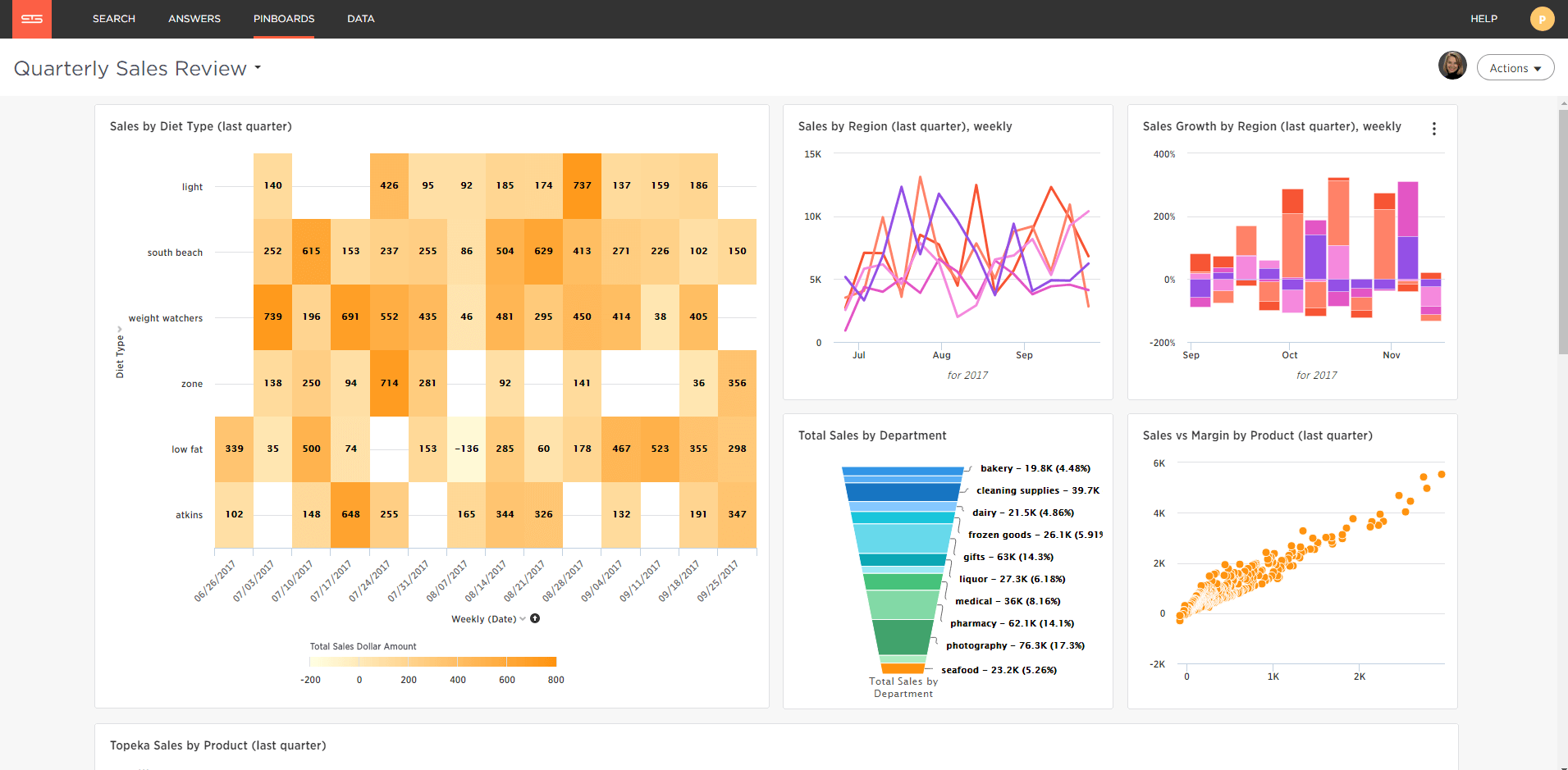
If this is a report I want to keep I can pin it to my pinboard as shown below.
Using the ODBC/JDBC method you can typically expect to transfer up to 300GB/hr for 4 nodes, however using tsload you can expect transfer rates in the region of 1TB/hr with 4 nodes and scales as you add nodes.
If you would like to know more about how Datalytyx can help with all things ETL, Data warehousing and BI then don’t hesitate to contact us.
0 Comments