")
This is a demonstration of how you can use Azure Databricks to build a recommendation algorithm from your Snowflake database tables. We use the publicly available Netflix movies data, a record of 100 million movie ratings by Netflix users. This is publicly available data from the machine learning competition website Kaggle.
I will show you how with Azure Databricks you can:
- Spin up a Spark cluster
- Load data from Snowflake
- Visualise data
- Build a recommendation system for Netflix movies
- Push recommendations back into your Snowflake database
Click on the images below to open the live snippets. You can also download all the snippets used here in a zip file.
Spinning up your cluster
In the Azure Databricks workspace of your choice, navigate on the left hand side of the UI to Clusters. Click create cluster. To follow this demo exactly, you need to fill in the following options:
- Cluster Name: DataScience-Cluster
- Cluster mode: Standard
- Databricks Runtime Version: 4.2
- Python Version: 3
- Driver Type: Same as worker
- Worker Type: Standard_DS3_v2
- Min Workers: 2
- Max Workers: 3
- Autoscaling enabled
- Auto Termination: Terminate after 120 minutes of activity
- No additional Spark configurations or Environment variables
Load data from Snowflake
The code below shows how to load two tables I have on my Snowflake instance: Netflix_ratings_wide, which contains the joined data of the ratings with the movie titles dataset, and the Netflix_movie_titles dataset which will provide a useful lookup within the analysis.
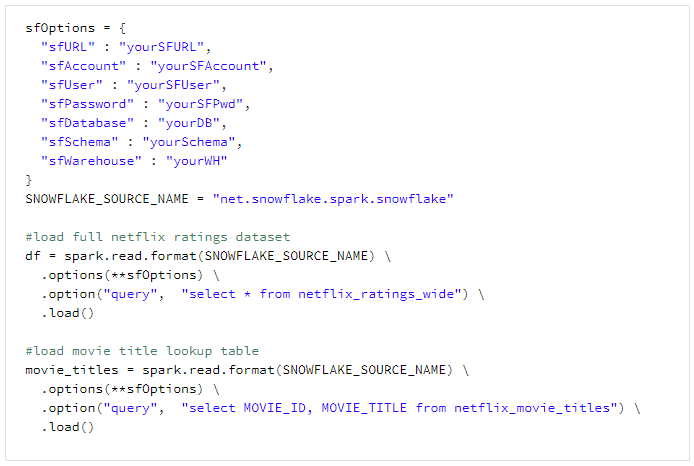
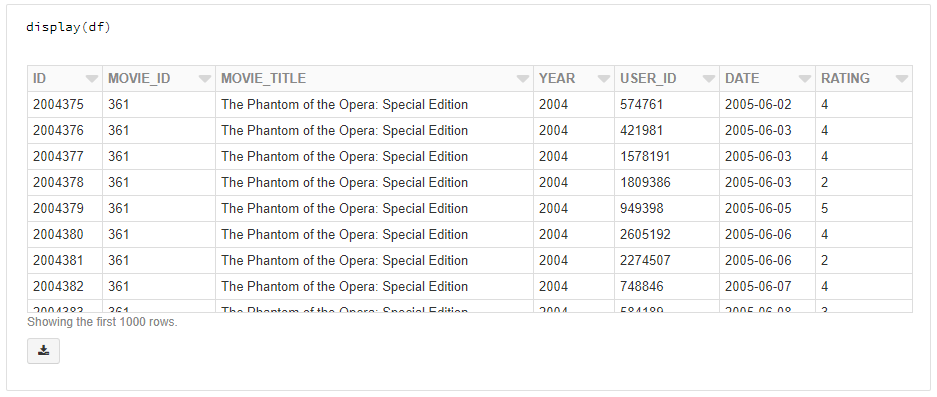
Now, after running that we have two Spark dataframes loaded into the cluster; df and movie_titles. In Databricks you can do a simple display(df) as below to view the top 1000 rows of the data and perform some interactive visualisation and sorting.
Data visualisation with ggplot and Seaborn
A key part of any machine learning project is exploratory data analysis to better understand the data at hand and pick up on any nuances or trends early on.
Two of Data Scientists’ favourite visualisation packages from Python and R, ggplot and Seaborn, are available automatically in your cluster. Below shows two example visualisations and the code used to produce them; one showing the distribution of the average movie rating, and another showing a small sample of movies with their rating inter-quartile ranges.
(First)
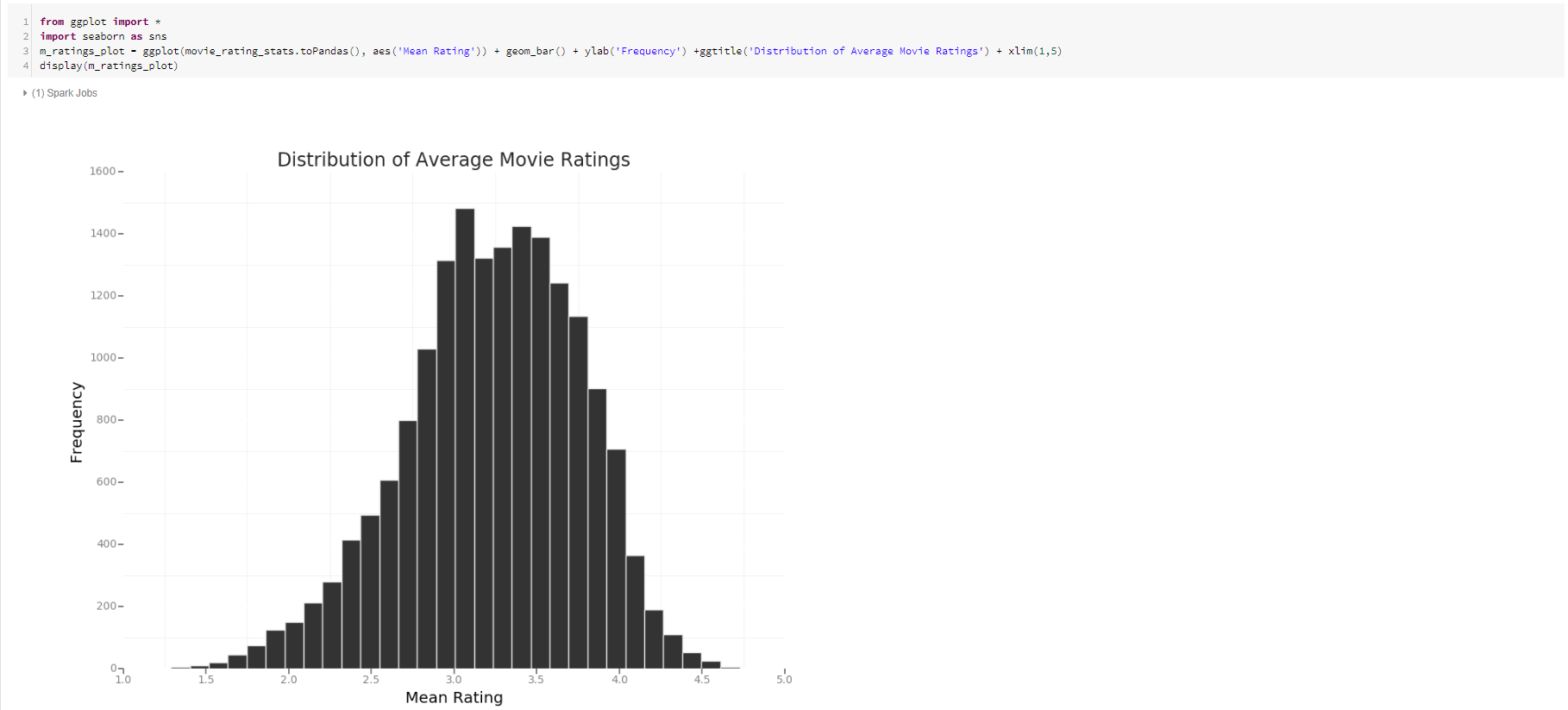
(Second)

Build a recommendation system for Netflix movies
Now let’s recommend some movies! We will use the alternating least squares (ALS) algorithm to provide 3 recommendations to each user based on their ratings history. This algorithm uses clever matrix factorization techniques to combine information about both users, movies, and the ratings to produce recommendations. If you would like to go into the nitty gritty details of this method, I would recommend this blog post (https://datasciencemadesimpler.wordpress.com/tag/alternating-least-squares/#ALS). ALS has been the go-to recommendation algorithm for many of these problems (known as ‘co-clustering’ problems) and hence has seen some sophisticated development in the Pyspark open source machine learning capabilities. That’s why we can fit and apply a recommendation model in only 6 lines of code. First we create the als object which defines the users, items (movies) and ratings of the dataframe. Then we fit the model using als.fit(df), and gather 3 recommendations using model.recommendForAllUsers(3).
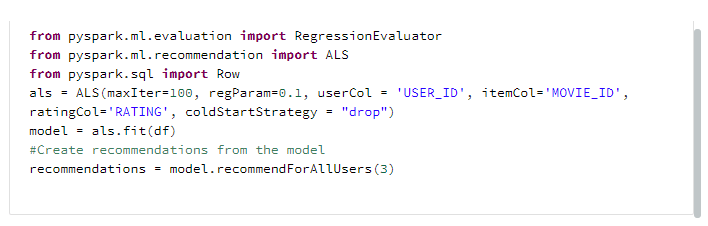
After a few simple transformations of the output, we get the final_recs dataframe which provides us with each user’s recommended movies.
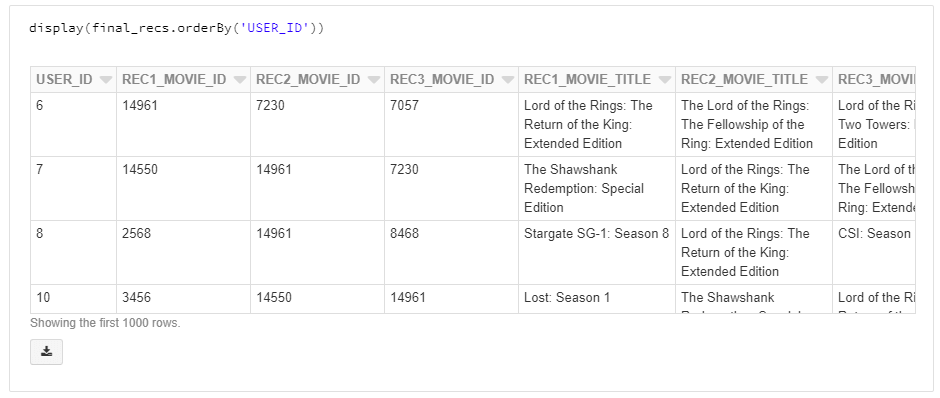
Then, we want to send this output dataframe to our Snowflake database as a new table. Turns out this is a simple one liner, too.

Conclusion
We showed the power and simplicity available with Azure Databricks. In a short amount of time and minimal code, we were able to extract over 100 million rows from Snowflake, fit and apply a recommendation algorithm to each of the users in the dataset, and send the results back to Snowflake as a shiny new table. The beauty of it all is that the cluster auto-scales and can be shut down (or will automatically do so if you forget) as soon as you are done with the processing. Forget the days of hardware maintenance, complex Dev Ops and huge scaling costs. Large scale machine learning is no longer a difficult dream but a simple reality.
0 Comments