
Doing silly things
There’s a time-honoured tradition of doing stupid things with powerful tools as a way of showing their capability. Notable examples include cranes, trucks, and of course robotic fruit surgery.
By accomplishing something difficult but pointless in an interesting way, you can show off a product, skillset, or even how much money you have while also hinting at how that thing could be used in real life.
Technology and data demos so often start with “so here’s a fictional company selling widgets”. I think we could do something slightly more unusual. So here’s a completely pointless example of using DataOps.live to read the news.
When working in Snowflake, the sensible way to read the news would be to open a new tab and go to your website of choice. The silly way to read the news would be to have a table called ‘NEWS’ with a row for each story.
The stupidest way to read the news would be to create a table for each news story, set the description for the table to be the title of the story, then create a column called URL with a description of the link, and have that whole process update on a schedule.
So let’s do that.

I got SOLE
DataOps.live has a feature called SOLE – the Snowflake Object Lifecycle Engine – which allows us to take a declarative approach to creating Snowflake objects.
In practice that means we can add a .yml file to our DataOps.live project which defines the warehouses, resource monitors, databases, schemas etc., and the pipeline will create them for us.
It’s smart enough to create them if they don’t exist or to modify them if they do. And there are great use-cases for this such as programmatically defining resource monitors to apply to your Snowflake warehouses, or using different values for different environments. We’ll come back to this later.
The database IS the news
[Disclaimer: this is practically the definition of an anti-pattern. If you’re trying to do what I’m doing here – don’t! Your DBA will have a heart attack. Get in touch and we’ll talk.]
We know SOLE can read a .yml file from its repo and use that to create database objects. But what if we can’t specify everything in advance? For example, because you want to create a news-reading interface within the Snowflake UI?
DataOps.live has another useful feature to help us. It can run Python scripts as part of a pipeline. Normally this is used for things like file manipulation before loading into Snowflake or data modelling that can’t be pushed down into Snowflake. But in this case we’ll use it to call The Guardian’s news API to retrieve the current top 10 stories from their ‘World News’ section*.
Our DataOps.live pipeline has a step where it gets the script from the repository, loads the dependencies and secrets, and runs it.
How do we keep the secrets out of the repo?
Like all secrets in DataOps.live they can be stored in an encrypted text file on a server or in a dedicated vault like Amazon Secrets Manager. In this case the API key and Snowflake credentials are stored on the runner VM where this job is executed, and are only loaded at runtime.
I won’t go through the Python script in detail because I’m not a Python expert. In summary it calls the API, adds the stories to a list, then constructs an output yml file using ruamel.yml.
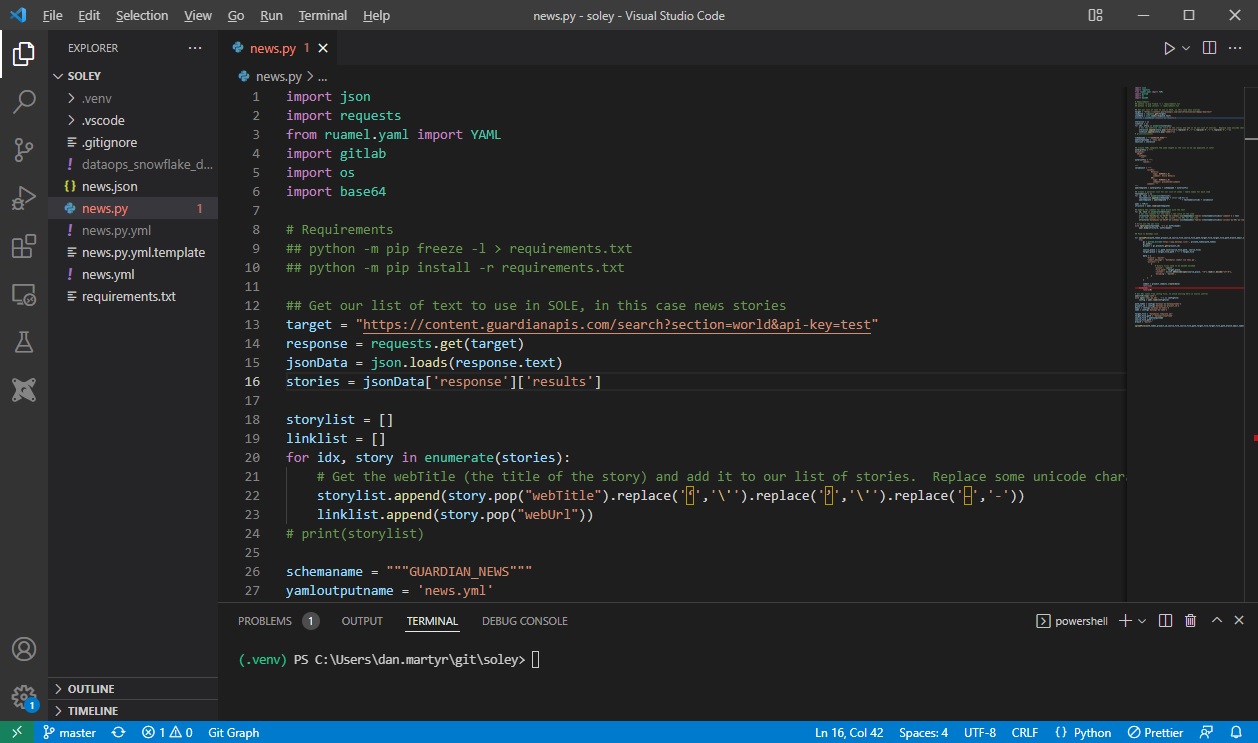
Finally, it commits that file back to the DataOps.live pipeline repo, which then automatically triggers a pipeline to run.
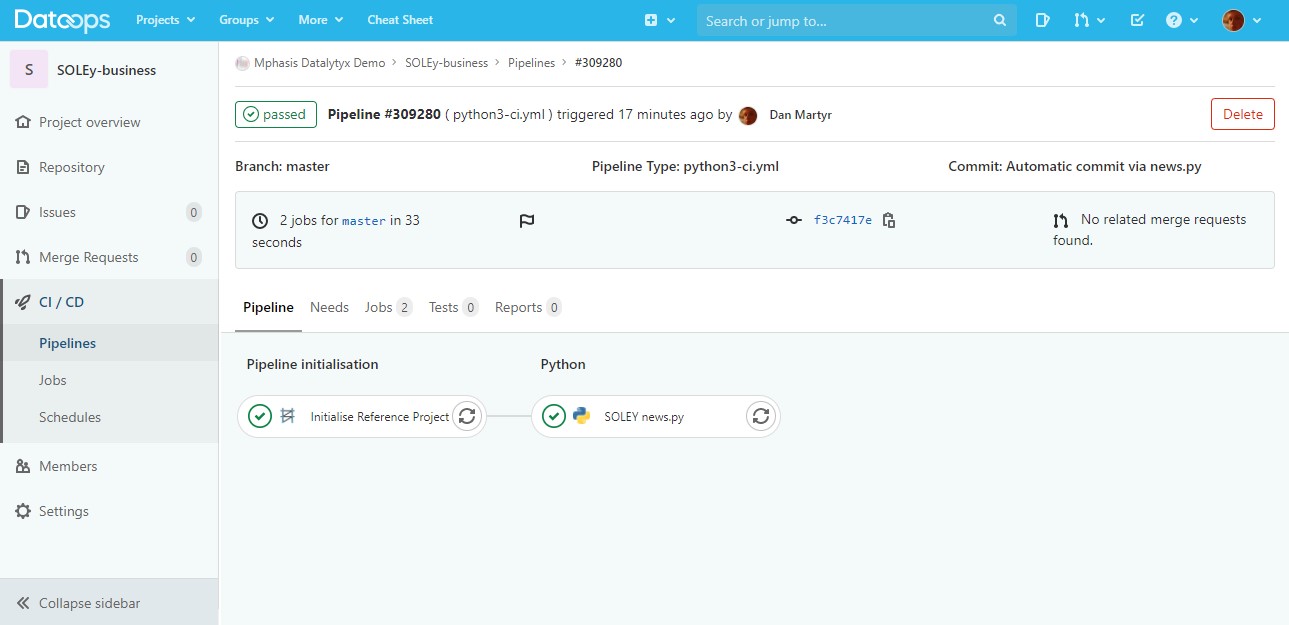
That pipeline then uses the new .yml file we just created to create a set of resources in Snowflake. The result is the set of tables as wanted, with the headlines shown in the comments fields.
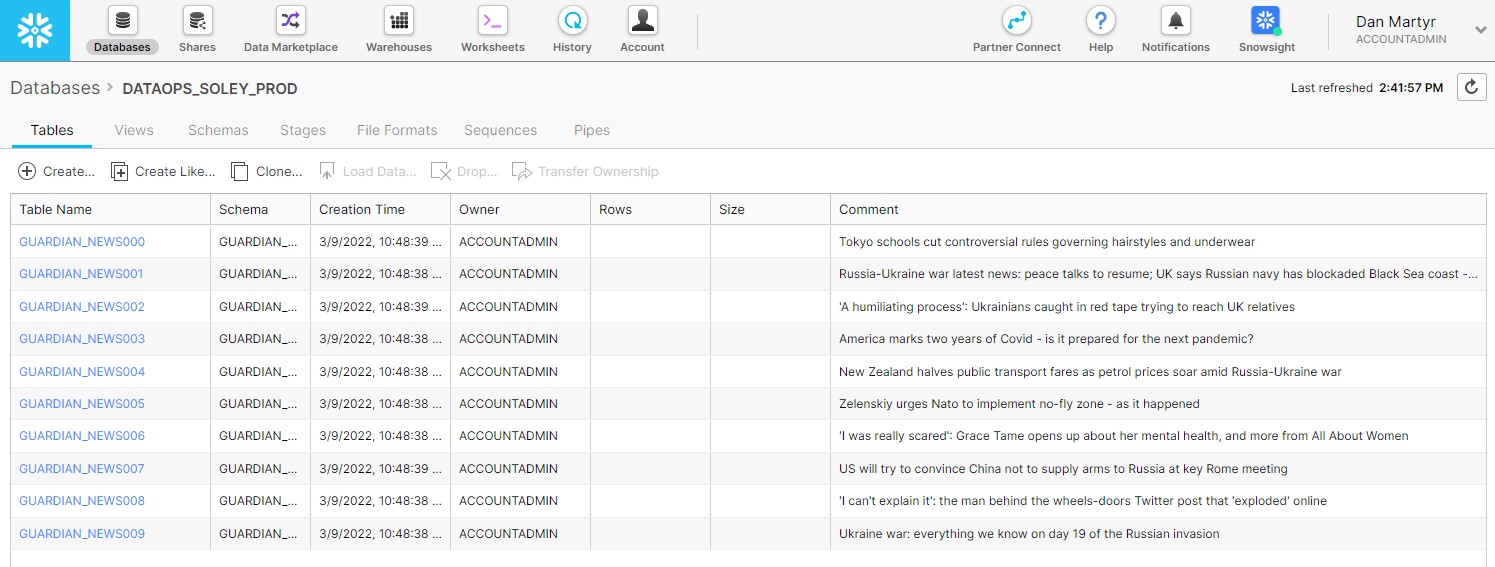
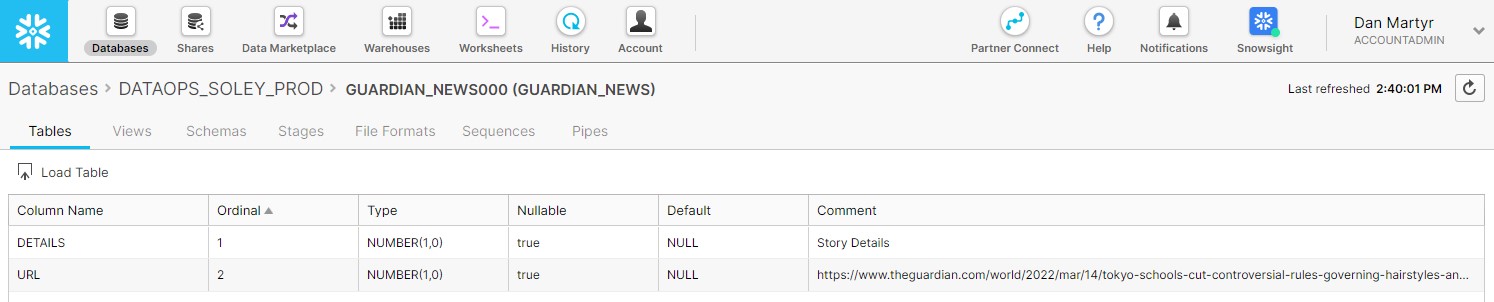
Sensible time
I mentioned earlier how we can use SOLE to do things like creating resource monitors from pre-defined values or Jinja rules.
What if we want to use more complex rules which use more complex logic, external libraries, or to retrieve those values from another system via an API?
This python-based approach would work well. We might have department or user information stored in Active Directory which we could use to specify Snowflake usage limits. Or maybe we want to define certain roles and grants in Snowflake based on data from Salesforce.
This approach also highlights how DataOps.live can be extended in a number of ways. In this case it’s calling scripts to do arbitrary things.
We have all the power of Python and any libraries we want, but it’s all still managed and executed from within our pipeline.
The end
Thanks for making it this far, I hope you took as much Rube Goldberg-ian delight from this as I did.
If you have any suggestions for v2, or if you’d like to discuss how to solve a real business problem with data and #TrueDataOps, contact me here: datalytyx.com/contact-us/.
* I hope by the time you’re reading this, the news is better. If not, please consider a donation here: https://www.linkedin.com/feed/update/urn:li:activity:6907222846100361217/.
0 Comments