
The introduction to Data Quality Profiling (part one of the Data Quality series) focused on data discovery by means of performing statistical data analysis. This blog – part two in the series – aims to perform pattern match analysis and validations using Talend Studio for Data Quality. For the purpose of this exercise, I have established a connection to Salesforce and we will be using contacts table for our analysis.
What are Patterns?
Patterns are variations of values stored within a column. The table below shows an example of values and their respective patterns.
| Column Values | Patterns |
| John | Aaaa |
| john | aaaa |
| 1987 | 9999 |
| 19/01/1957 | 99/99/9999 |
Why is Pattern Matching and Validation important?
Pattern match analysis groups patterns by values within a column. These patterns can then be used to standardise data sets by validating the data against business logic. For example, the column “Status” below should always have “Active” or “In-Active” values only. When you run a pattern match analysis you may find a number of nulls and/or different values that should not be present in this column.
| Status |
| Active |
| In-Active |
| active |
| inactive |
Pattern matching helps you discover the various patterns (values) within your data and validate the values against your organisation’s business logic. Validation is performed to check the integrity of the data and forms the basis of performing data cleansing activities.
Pattern Match Analysis
The analysis aims to investigate patterns of phone numbers, dates, postcodes and email addresses. In order to run the analysis I have established a connection to Salesforce and the table used for pattern matching is called ‘Contacts’.
I have set up a new single column analysis in Talend (please see part one for information on how to do this) in order to perform pattern match analysis. I will be using the following columns from the ‘Contacts’ table:
- MailingPostalCode
- Phone
- CreatedDate
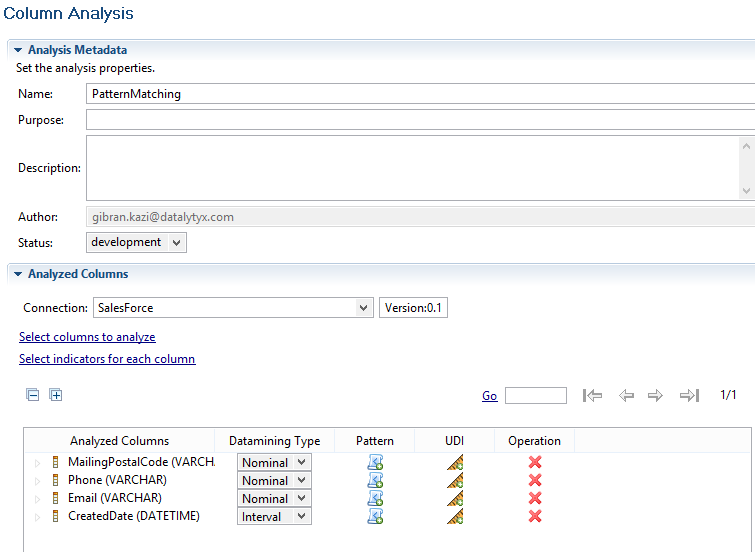
In order to get an overview of the column values and group them by patterns, “Pattern Frequency Table” is the only UDI (User Defined Indicator) selected (for more details on UDIs, please refer to part one).
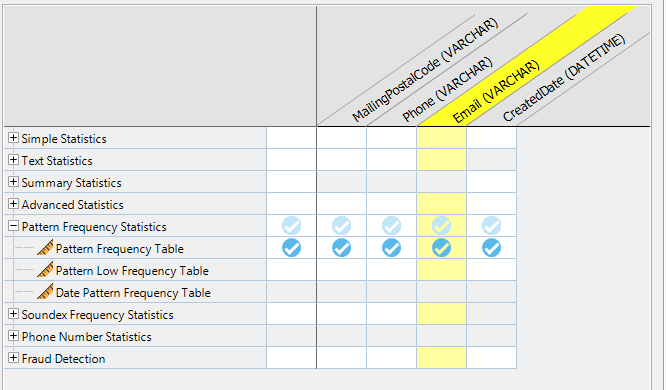
Analysis Results
The results below indicate that the Postal Code has a number of nulls as well as a mix of alphabetical and numeric values within the data. We could assume that the numeric values could be US zip codes. Further analysis can be performed by drilling down into the data or saving one of the patterns in the repository for re-use or validation against different columns within the same or different tables. Talend also allows you to create a regular expression from the bar chart itself.
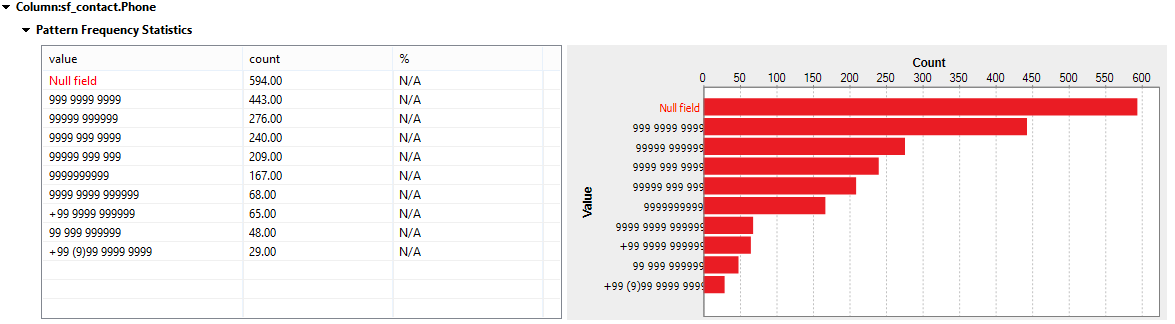
The Phone field has numeric values, as expected. The bar chart below indicates the different format of stored phone numbers. Cleansing the data will require telephone number validation first, based on regular expressions (covered in ‘Validation’ later in this blog post).
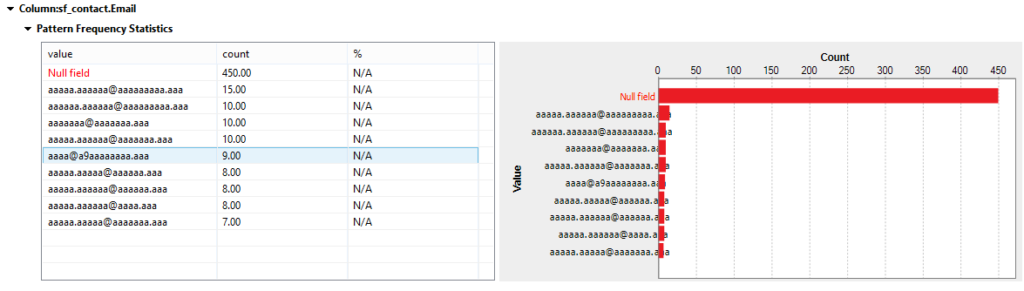
The results below provide an overview of patterns within the Email column. It indicates that there are a large number of null values in the data. Validation of email addresses can get tricky. However, regular expressions (or regex as they may otherwise be known) for validating emails are available in the repository and will be covered in the next step of this blog.
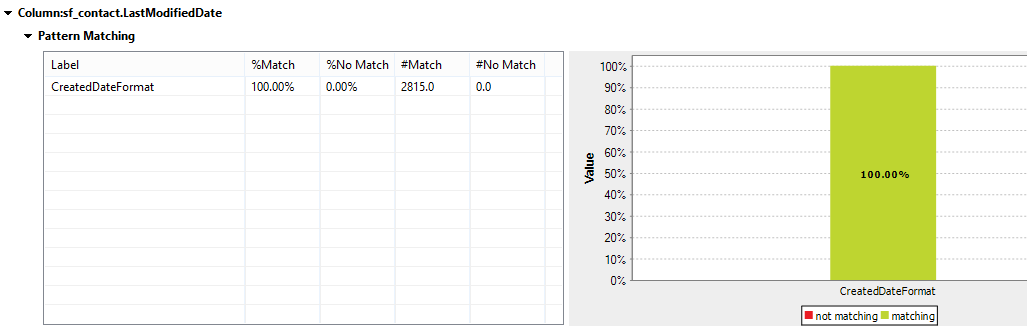
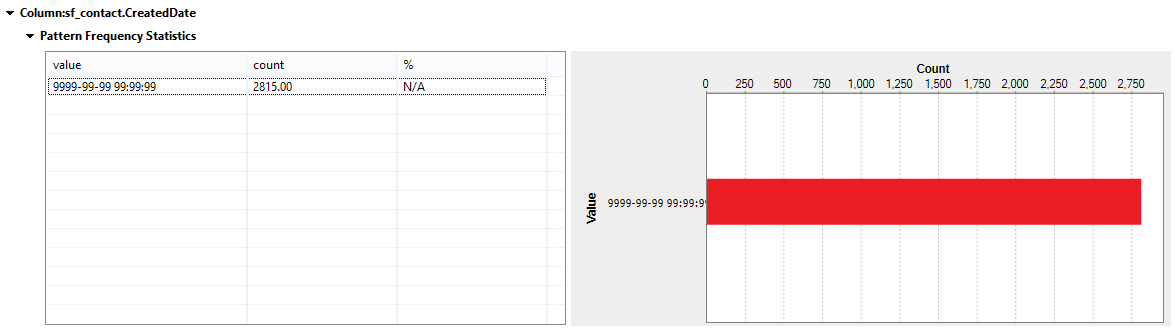
The CreatedDate column is one that can cause issues if the date values are stored incorrectly in the database. Queries based on dates for retrieving rows from or inserting rows into the database should always have the same format. The results in our analysis show a single pattern value within the CreatedDate column. We can now save this pattern to run against other date fields. The reason to do so is to check whether all date fields within the table have a standard pattern. You can also set thresholds to check whether any rows inserted over time match the same pattern.
Validation
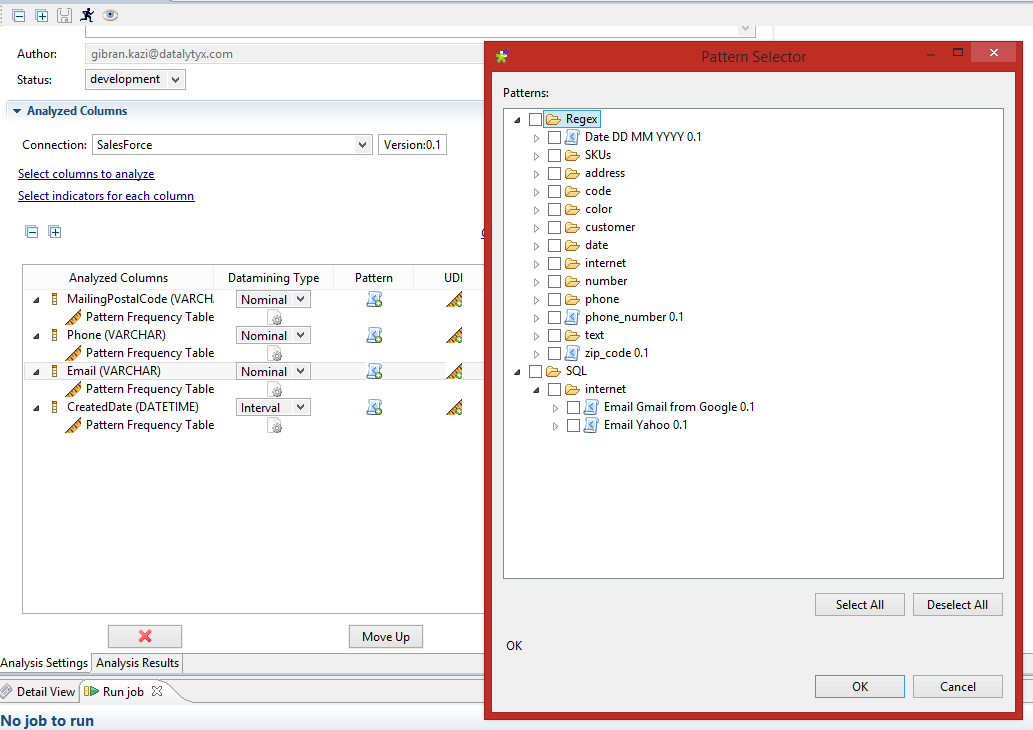
The purpose of this step is to check the quality of the data based on regular expressions and SQL queries. Talend has an enormous open source community that develop and share expressions, queries and components. For this exercise we will use regular expressions/queries available within the Talend Studio.
In the same analysis, select a regular expression or query from the list by clicking on the following symbol:
![]()
You can select multiple patterns for each column. Even a combination of regular expressions (regex) and UDIs can be selected.
Validation Results

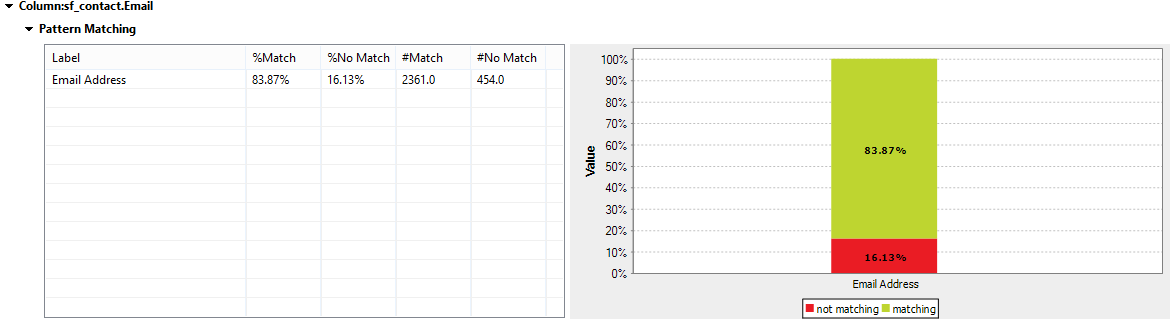
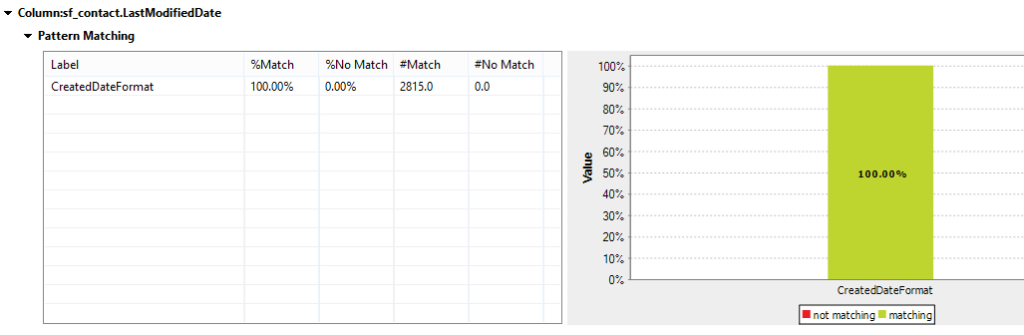
Conclusion
In this blog we have performed pattern matching on different fields and evaluated the integrity of the data within those fields. An example where pattern matching and validation can be performed to a business advantage is prior to a marketing campaign. Analysing can help focus on the quality of the data and form the basis of cleansing data; prior to emails, posts or any other form of contact is made to the customer. The next blog (part three) will cover the topic of data cleansing in an integration job based on the results of data quality analysis.
Appendix
Regular Expressions used:
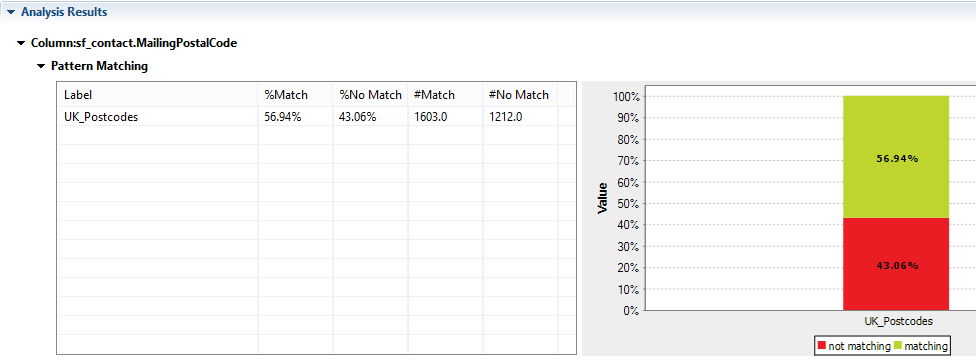
| UK_Postcodes | ‘^(GIR ?0AA|[A-PR-UWYZ]([0-9]{1,2}|([A-HK-Y][0-9]([0-9ABEHMNPRV-Y])?)|[0-9][A-HJKPS-UW]) ?[0-9][ABD-HJLNP-UW-Z]{2})$’ |
| Phone Number | ‘^([a-zA-Z,#/ \.\(\)\-\+\*]*[0-9]){7}[0-9a-zA-Z,#/ \.\(\)\-\+\*]*$’ |
| Email Address | ‘^[a-zA-Z0-9._%-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4}$’ |
| CreatedDate format (custom) | ‘^[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9] [0-9][0-9]:[0-9][0-9]:[0-9][0-9]$’ |
0 Comments