
What are Snowflake Customers asking for today?
Data Governance is at the core of what many Snowflake users want. As Frank Slootman said, after coming back from his recent “Black Diamond Executive Council” roundtable discussion between Snowflake and a dozen of their key customers worldwide:
“Data governance is a key driver for customers choosing Snowflake. Beyond cloud scale and performance, our major enterprise customers are signalling that one of the most critical values delivered by the Snowflake Cloud Data Platform is the measure of data governance the platform affords them. Basically, they’re saying, “When my data is in Snowflake, I know it’s governed. And therefore, I can rest easy.” And they’re right.
When you ingest data into a cloud data platform through defined processes and it’s controlled, managed, and monitored by a single security model, you make great strides toward data governance, especially compared with traditional data lakes. Data lake initiatives often boil down to improving storage economics through data consolidation, but the benefits get thin after that. And as we’ve pointed out before, the security provisions in a data lake are in many areas an exercise left to the user, and have- led to several high-profile breaches.”
– Governing Data, Frank Slootman
So, Snowflake automatically brings with it data governance that traditional data lakes do not. However, customers still need to respond to demand from their business users with agility and speed. There is still a tension between Governance and Agility, as Kent Graziano, Chief Technical Evangelist at Snowflake, comments:
“I speak to our biggest customers all over the globe frequently, and many of them are asking me about agility and governance. They ask me questions like ……. how can I do CI/CD for Snowflake so I can deliver value faster?”
– Kent Graziano, Chief Technical Evangelist at Snowflake
Who is asking for CI/CD, why do they need it, and what’s the challenge?
In the world of cloud software development, Continuous Integration / Continuous Deployment cleverly allows enhancements and bug fixes to be deployed without any downtime, as soon as they’re ready and without users even noticing (except when they see a fix or new feature). At the same time, CI/CD provides version control, automated testing, change control processes and automated release management. Having one, integrated CI/CD process led to the birth of “DevOps”, where developers also impact operations; their toolset is one unified process of making and deploying changes – both agile and governed.
Until recently, data engineers could only dream of having something similar to their software development brethren. What if you could combine the agility of rapidly changing data ingestion and enrichment with the governance enterprises need to stay in control of their key data assets? Some sort of CI/CD for data, with data engineers becoming “DataOps”.
Legacy data warehouses, like earlier software development environments, just didn’t have the tools and technologies to enable this. Not without spending megabucks. But Snowflake is now showing the way; the pipe dream is becoming reality.
When they consider it, data engineers can see their organisations would benefit from DataOps. Now, because they are launching into a new paradigm by moving their data into the cloud with Snowflake, and because Snowflake has the features to support it, there is an opportunity to deliver on the promise of agility through a governed and auditable CI/CD process.
Starting the DataOps journey
Data engineers quickly learn that CI/CD for data extends beyond simply managing tables and pipelines. Rather it starts with where they get the data and ends with where they deliver it to, or who they share it with. CI/CD covers the entire data pipeline from source to target, including the data journey through the Snowflake Cloud Data Platform. They are now in the realm of DataOps – the next step is to adopt #TrueDataOps.
DataOps not a widely-used term within the Snowflake ecosystem. Instead, customers are asking for CI/CD for Snowflake. But CI/CD is only one pillar of the seven pillars of #TrueDataOps.
When the issue of CI/CD is raised, we need to ask those same customers if they also need or want any of the other pillars:
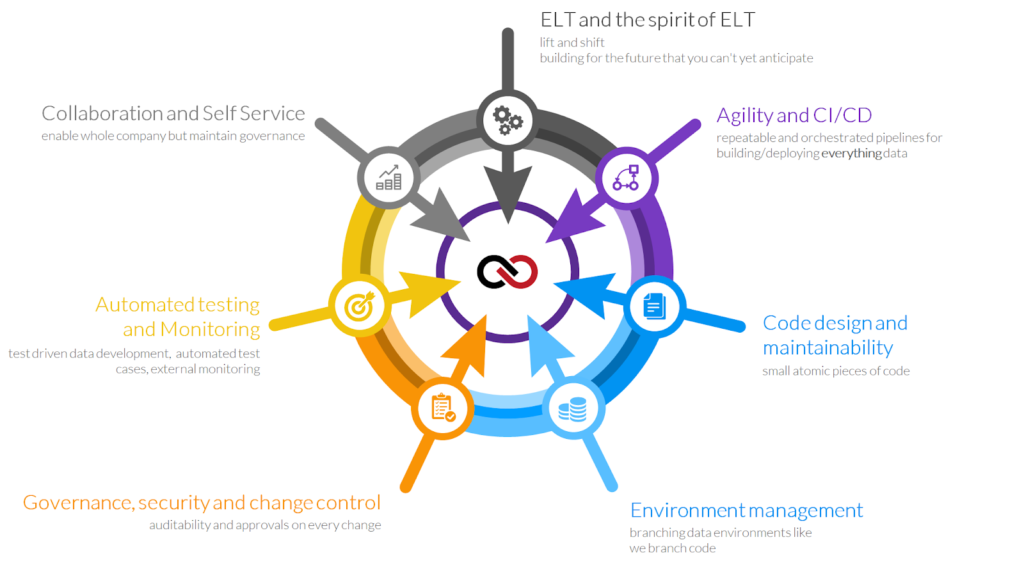
If they say “yes” to even a few of those pillars, they are asking for more than “just” CI/CD for Snowflake. They are asking for DataOps for Snowflake.
Why is Snowflake the perfect platform for #TrueDataOps
Snowflake is an analytical data warehouse provided on a Software-as-a-Service (SaaS) basis. Unlike many other providers in the data warehouse marketplace which rely on existing technologies like Hadoop, Snowflake uses its own SQL database engine with a unique architecture natively designed for the cloud.
This architecture has enabled some powerful Snowflake features which make it unique in its ability to support a #TrueDataOps approach.
Environment Management
One of the key requirements of any DataOps approach is the ability to natively and automatically handle multiple environments. This includes well defined environments e.g. Production, QA, Dev. But it also includes the ability for any developer to dynamically create their own complete and self-contained environment when they are working on a specific use case.
By creating multiple virtual warehouses and sizing them appropriately to the workload, Snowflake allows these environments to be completely isolated from each other. No work in Dev can ever negatively impact QA or Production. Furthermore different virtual warehouses can be used for different workloads operating on the same data, e.g.:
- To separate ingestion and transformation workloads so they are more performant
- To separate transformation workloads from user queries to prevent interference
This separation significantly reduces risks to production systems and strengthens compliance and governance without reducing business agility.
Any developer would love their own dedicated environment to work on a new use case, and for that environment to be as close as possible to Production (identical even). In DataOps for Snowflake ™ we call these Feature Branch Databases. However, in the busy real world where more than one new thing is being developed at once, storing tens of copies of Production would be wasteful. Worse, having all these environments ingesting data from the same source systems would bring most of them to their knees.
The solution is Snowflake’s Zero Copy Cloning. This allows even the largest (multi TB or larger) Production Databases to be cloned into any number of other environments quickly and with no duplication of actual data stored. Thus any developer can automatically create a Feature Branch Database and develop and test their changes in a perfect sandbox at a moment’s notice. Zero Copy Cloning is unique to Snowflake, and results from their innovative cloud architecture. In DataOps for Snowflake ™ these Feature Branch Databases are generated automatically in seconds:

Automated Testing
One of the most critical components of DataOps is Automated Testing. This is the ability to test, in a fully automated fashion, that data ingested or transformed is valid before it is shown to business users. This replaces a traditionally manual, very time consuming activity that is typically done all too infrequently and is at best a ‘spot check’.
With DataOps, there is a full automated process run any and every time data changes. Here, there is are a trade-off of expensive ‘people time’ for cheap ‘compute time’. In DataOps for Snowflake™, the Automated Data Testing Framework uses Snowflake’s Auto Scaling to allow hundreds or thousands of tests to be run across entire datasets in seconds, automatically testing and validating data every time it changes.
Intensive Tasks
When there is a single very intensive task then AutoScaling a cluster isn’t the answer. Fortunately Snowflake allows us to change the size of a virtual warehouse programmatically and extremely quickly (for example from small to large). DataOps for Snowflake ™ can change the virtual warehouse size at the start of a job doing an intensive task to process the workload quicker. Once complete, the virtual warehouse is then reverted back to its previous size.
This video shows that process in action as we set an unofficial data ingestion record by loading 100 databases into Snowflake using DataOps for Snowflake ™ .
Building for a future you can’t yet know
Data sources are changing all the time, often dynamically. The #TrueDataOps philosophy includes the spirit of ELT – Extract, Load, Transform – where the data ingested should be all of the data. With DataOps for Snowflake this is metadata-led, automatically discovering and tracking the make-up of each data source, capturing everything rather than a subset. Ingestion is quick, comprehensive and decoupled, so that data processes won’t break when things change.
Data is increasingly offered for ingestion in the form of JSON messages. Rather than dealing with any transforms in flight, everything can be written directly to tables in the ingestion layer as VARIANT types. By building intelligent transformations (including flattening) on top of this data, a Data Warehouse can achieve both high flexibility in terms of ingesting data with changing schema AND a highly governed and controlled structure on top of this as required by Analytics and BI users. The Modelling and Transformation engine in DataOps for Snowflake ™ is used to model all flattening and transformation of semi-structure and structured data, but generates push-down SQL into Snowflake to actually execute this. Once data has been landed in Snowflake we don’t want to lift it out again until users are actually consuming it.
Agility and CI/CD
Achieving true agility and delivering value, at the speed a business wants, means spending the majority of time focussing on the meaning and value of data. Tinkering with indexes, partitions and distribution keys in order to achieve acceptable performance or meet business SLAs is an avoidable waste of data engineering resources. Snowflake’s unique approach to metadata driven optimization eliminates many of these tasks automatically so engineers can focus on delivering value.
However, there are still database decisions that need to be made and traditionally teams spend a lot of time designing complex database architectures to improve performance. This optimisation was required in many legacy database platforms because of query optimisation limitations and limited compute capabilities.
With Snowflake, most of this work would constitute premature optimisation. Why? The query optimiser in Snowflake may well handle many of the expected queries perfectly well without any further optimisation and complexity. For the small number of features that don’t perform, when in DataOps for Snowflake™ getting a new feature up and running can happen in hours, and changes can be made in minutes, you can quickly identify the few features you need to optimise, and resolve them quicker still.
In the era of cloud native data platforms like Snowflake, premature optimisation delivers very little value. But it creates a lot of additional complexity and can cripple the agility of a team trying to meet the urgent requirements of the business.
What is DataOps for Snowflake ™
DataOps for Snowflake™ is a technology implementation of the Seven Pillars that underpin the #TrueDataOps philosophy.
DataOps for Snowflake™ has been designed to exploit the most advanced features of Snowflake, to enable regulated and unregulated organisations alike, to explore the power and agility of DataOps to accelerate the delivery of business value, while making zero compromises in terms governance and security.
While a few DataOps platforms will support some of the pillars of #TrueDataOps, DataOps for Snowflake™ is one of the only platforms to support ALL of those pillars.
A DevOps CI/CD pipeline has three very standard stages:
- Build – get all the required code, dependencies and do any required compilation and packaging. This often includes interacting with 3rd party systems. This produces a candidate artefact – typically a software/container image.
- Test – take the generated artefact and subject it to a range of tests to confirm that “it’s good” and good to deploy. If it’s not then stop here and raise alerts.
- Deploy – take the tested artefact deploy it into production, usually replacing an older one.
In DataOps for Snowflake we have all the same concepts, but some of the details change. Let’s consider that in a DataOps pipeline the artefact isn’t a software binary or a container image, but a complete set of Data Warehouse structure and data ready for business consumption i.e. everything a user needs to gain insight.
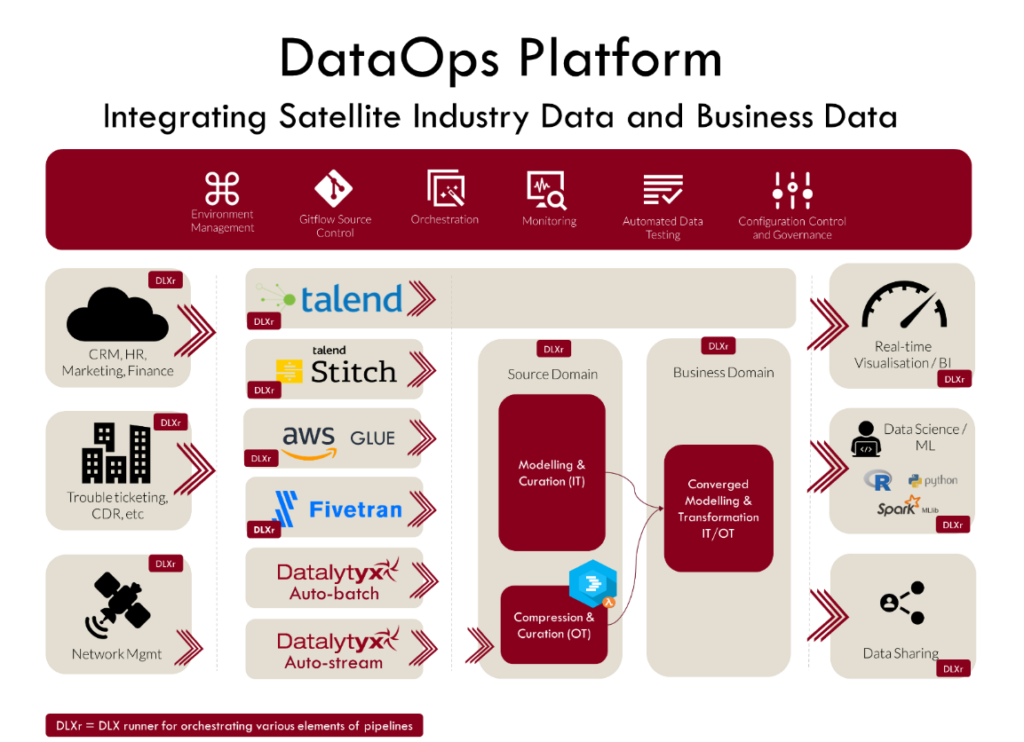
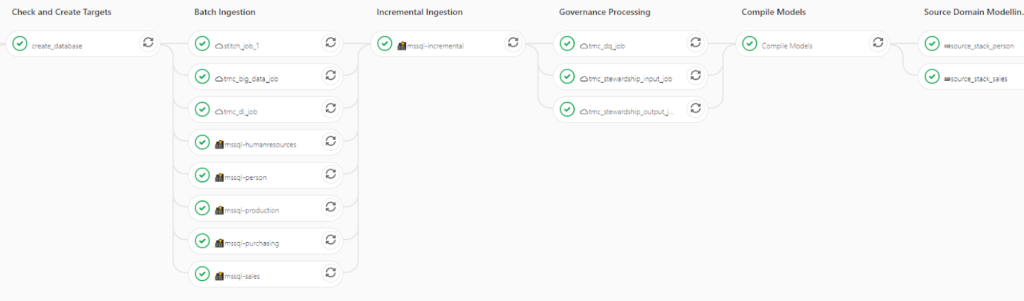
- Build – get all the required code and dependencies. In this case the dependencies includes ingesting data from a source systems, either directly using the DataOps Auto Ingestion capabilities and/or by orchestrating 3rd party tools such as Talend, Stitch, fivetran, Matillion, Glue, etc. Since we are usually following an ELT model, the data ingested doesn’t meet the needs of the business users, so we compile a set of models to transform the data through various layer to get it to the desired state and structure. We now have a candidate artefact. It may be a database inside Snowflake rather than a software image, but this is only a implementation difference, the concept is the same.
- Test – take the generated artefact and subject it to a range of tests to confirm that “it’s good” and good to deploy. If it’s not then stop here and raise alerts. Nothing really changes – the nature of the artefact is different and the test are of course written differently using the DataOps for Snowflake Data Test Framework the principles are identical.
- Deploy – take the tested artefact deploy it into production. Again, the implementation is different, but the concept is the same – once we have a new and better (either because it has new functionality or just newer data) artefact we can deploy it at a time of our choosing.
Data from your applications and systems is extracted and loaded into the Snowflake data lake orchestrated by DataOps for Snowflake™ runners, but without applying any transformations to the data. This is ELT and the spirit of ELT.
Once loaded in the “Source Domain” zone of your Snowflake Data Platform, data engineers and analysts can concurrently and collaboratively prototype and develop data models for testing, design the data pipelines that will deliver the analytics requested by stakeholders, and build the automated tests to ensure these transformation pipelines won’t break now or in the future.

Once passing all the automated testing, the code can be pushed into production where ongoing monitoring provides instant alerts when a problem is detected. Importantly, changes to code and data can be rolled back almost instantly using the Gitflow Source Control features.
DataOps for Snowflake has been designed to orchestrate the entire end to end process, and the various pipelines that ingest and transform data, and ready for consumption in your chosen format. Enhanced environment management capabilities enable the task of creating and removing environments for branches, features, and production itself.
And to ensure your business meets its compliance obligations, DataOps for Snowflake automatically creates a full audit trail to show what data you hold, how it may have been transformed, by who, and with whom it was shared. You can apply additional configuration controls to maintain complete oversight and to prevent accidental loss or leakage.
DataOps for Snowflake is ground breaking as the first DataOps platform to truly embrace all the core principles of DevOps and deliver them without compromise.
Conclusion
Around 10 years ago infrastructure teams were fed up with manual, error prone, time consuming creation of infrastructure and looked longingly at the software world with it’s agility, automation, automated testing, repeatability etc and the Infrastructure as Code movement was born. It’s now inconceivable that any enterprise would consider creating, setting up, maintaining and scaling their infrastructure by hand. In fact virtually all Enterprise IT follows this pattern now – all except Data.
Why not? Simply put, the tools and technologies didn’t exist to allow it. It’s hard to script the physical task of bolting a server into a rack, it’s much easier to script the creation of a VM on top of an existing server, and easier still in the cloud where you can just forget that physical hardware even exists. Virtualisation and then cloud computing enabled Infrastructure as Code. As the first Cloud Native Data Warehouse, Snowflake has enabled #TrueDataOps.
Tools like Chef, Puppet, Ansible and Terraform were created to allow organisations to capitalise on this new promise and even more powerful systems were built on top of these. The DataOps for Snowflake platform was created to allow organisations to take advantage of these newly available cloud data warehouse capabilities.
With the ever present need to deliver value to the business more cost effectively and quicker while maintaining the highest level of security and governance, now is the time for every organisation to make the leap into #TrueDataOps.
We don’t mean a vague philosophy either – #TrueDataOps delivers:
- Actionable, accurate analytics that meet business needs and satisfy the changing demands of your stakeholders.
- Creates the environment required to deliver new features and functionality quickly and effectively without compromising the underlying data.
- Uses automation and technology to manage the tension between governance and compliance and agility.
We believe that to be able to deliver #TrueDataOps – you need technology to support the seven pillars of this philosophy.
In the early days of Infrastructure as Code, a few bleeding edge organisations built their own tooling, but very quickly this became a fragile and expensive liability to maintain. Despite being bleeding edge, they were rapidly overtaken by organisations who took new tools specifically built for this purpose that ‘just worked’ and allowed them to get on with actually delivering value. Until very recently the same has been true in DataOps space – with few if any proper DataOps tools available (and most of those on the marketing being old tools with a DataOps prefix added), anyone wanting to get these benefits had to build their own. Today that is no longer required.
Snowflake is the ONLY data platform available today that provide the features required to deliver DataOps in a modern cloud architecture. And the DataOps for Snowflake™ is the ONLY solution available today that exploits these features to deliver #TrueDataOps.
To learn more about DataOps for Snowflake from Datalytyx (link or call us)
0 Comments