
Have you heard of this thing called Data Mesh? It’s so hot right now…
Tech is not shy of a buzzword or three. Data Mesh is the latest of these buzzwords and we are already being swamped with different interpretations of just what a Data Mesh implementation really looks like. In my contribution to this Cambrian explosion of Data Mesh articles I will be sticking to first principles.
First principles, when it comes to Data Mesh, consist of the two blog posts by Zhamak Dehgani who is the originator of the term Data Mesh.
Articles from Zhamak
https://martinfowler.com/articles/data-monolith-to-mesh.html
https://martinfowler.com/articles/data-mesh-principles.html
Zhamak references some key architectural problems that are common in the current data landscape. These are the problems that Data Mesh aims to resolve. Zhamak also does a really nice job in the second article of articulating what the solution looks like at a conceptual level.
There’ll be no attempts to define a Data Mesh in this article. My focus will be on addressing Zhamak’s “architectural failure modes”. Later we may ask ourselves:
“If a solution addresses the architectural problems laid out by Zhamak, then is it a Data Mesh?”
What are the Architectural Problems?
In a nutshell, the individual domains within organizations are powerless to use the potential of their own data. This is due to the current approach taken when we architect and operate data platforms.
Instead, domains are relying on over-burdened centralized teams of data engineers. While these engineers have all the skills and experience to deliver data, they don’t understand the data as well as those in the domains. This organizational and technical structure leads to three key problems.
1. Centralized and monolithic
Most data platforms process data from many disparate sources across departments. The platform ingests data to a central data store. It then transforms the data to cleanse, manage and optimize for downstream analytics.
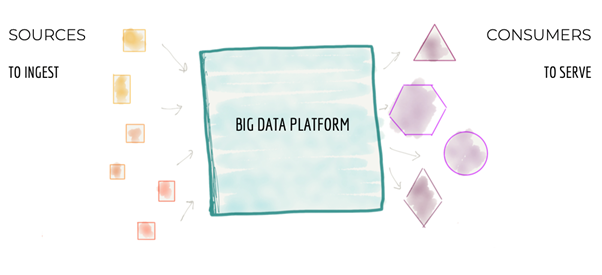
Source: https://martinfowler.com/articles/data-monolith-to-mesh.html
This approach works well on a small to medium scale. But what if we increase the number of data sources, the complexity of data, and the number of data consumers? Then this model creates a bottleneck. The platform is unable to keep up with the proliferation of data sources. And it can’t keep up with the increasing demands from a growing set of data consumers.
This story is familiar to anyone who has designed, built, or maintained data platforms for large organizations.
2. Coupled pipeline decomposition
A well-designed data platform will process the data in stages. Let’s zoom out and look at a data platform from a distance. There is a generic pattern that most if not all platforms will follow.
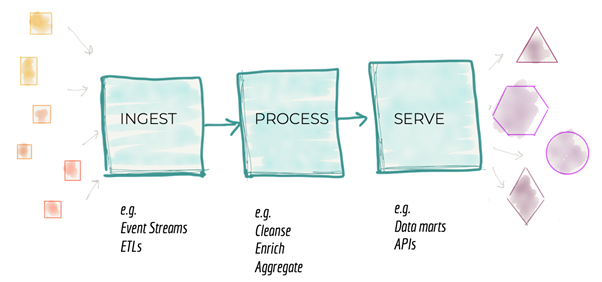
Source: https://martinfowler.com/articles/data-monolith-to-mesh.html
Organizations are managing their teams / workloads around these stages. One team is for data ingest. One is for processing. Another is for the data consumption (the serve stage). This is also not optimal.
3. Siloed and hyper-specialized ownership
Organizations usually isolate the domain expertise from the data engineering expertise. This is how organizations are set up. A data team provides a central data engineering capability to the whole organization. Every other domain is hyper-specialized and siloed from the data team.
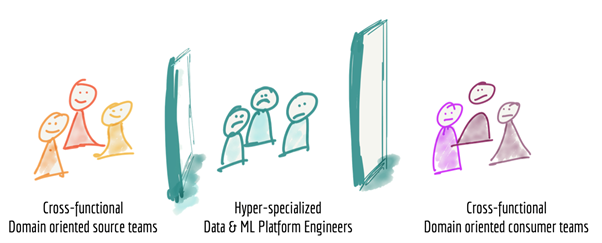
Source: https://martinfowler.com/articles/data-monolith-to-mesh.html
Let’s Tear Down the Modern Data Platform and Start Again!
…not so fast
There are a few things regarding these architectural issues that I could discuss in further depth. But it’s impossible to argue with the overarching message. We want to empower the domains within an organization to be able to use their data. We don’t want a centralized bottleneck preventing them from making the most of it.
A cursory skim of the articles might make you think that Data Mesh spells the end for many of the modern big data tools. Especially with quotes like this…
“To address these failure modes we need to shift from the centralized paradigm of a lake, or its predecessor data warehouse.”
At first, I was confused and quite concerned. What could deal with big and complex data if not a data lake or data warehouse?
Was she suggesting that we query data directly from the operational source systems? That’s not currently a viable solution for many reasons. Luckily, she addressed my concerns later.
“The physical storage could certainly be a centralized infrastructure such as Amazon S3 buckets but…datasets, content, and ownership remains with the domain generating them.”
“For this reason, the actual underlying storage must be suitable for big data, and separate from the existing operational databases.”
The current architectural problems are not due to technological constraints. Rather, it’s a combination of platform architecture and organizational structure.
So, now I think we can achieve Data Mesh with a small number of architectural and operational tweaks.
A Brief Aside: Battle of the Buzzwords – DataOps vs Data Mesh
Before DevOps was a thing there used to be a dev team (or many dev teams) and a central operations team. It became clear that the disconnect between the two disciplines was not optimal. As Atlassian put it, the two disciplines…
“railed against the traditional software development model, which called for those who write code to be organizationally and functionally apart from those who deploy and support that code.”
There is a parallel to be drawn between DataMesh and DevOps. Current data platforms call for those who facilitate the generation of data (the domains) to be organizationally and functionally apart from those who process the data (the central data team).
As DataOps is the de facto term for applying DevOps principles to the world of data I believe that the Data Mesh architectural problems should become a consideration when architecting a DataOps platform.
Perhaps it is obvious that there is no friction between DataOps and Data Mesh, but I would go a step further and say that Data Mesh becomes an aspect of the DataOps framework. I’m not saying you need Data Mesh to do DataOps, but it should be a design consideration.
Enter DataOps for Snowflake
So, can we get rid of the centrally owned data platform bottleneck? Can we usher in the age of the Data Mesh without having to throw the baby out with the bathwater?
The implementation of Data Mesh presents many challenges. Zhamak acknowledges two particularly important examples.
“As you can imagine, to build, deploy, execute, monitor and access a data product – there is a fair bit of infrastructure that needs to be provisioned and run;”
and
“what decisions need to be localized to each domain and what decisions should be made globally for all domains.”
Recently, Snowflake has made a substantial investment in DataOps.Live, which has developed DataOps for Snowflake.
Adopting DataOps for Snowflake addresses the challenges of implementing a Data Mesh framework. It embodies modern software development best practices by incorporating…
- Infrastructure as Code
- Testing
- Integration & Deployment
- all automated via CI/CD pipelines
DataOps for Snowflake provides the core DevOps framework. It also provides a framework for designing the data pipelines themselves. These are frameworks for HOW to deliver a data product in a repository.
Individual domains can just take a copy of the reference repository. Right away, they can focus on the business logic that they want. No more time and energy setting up the supporting infrastructure and processes.
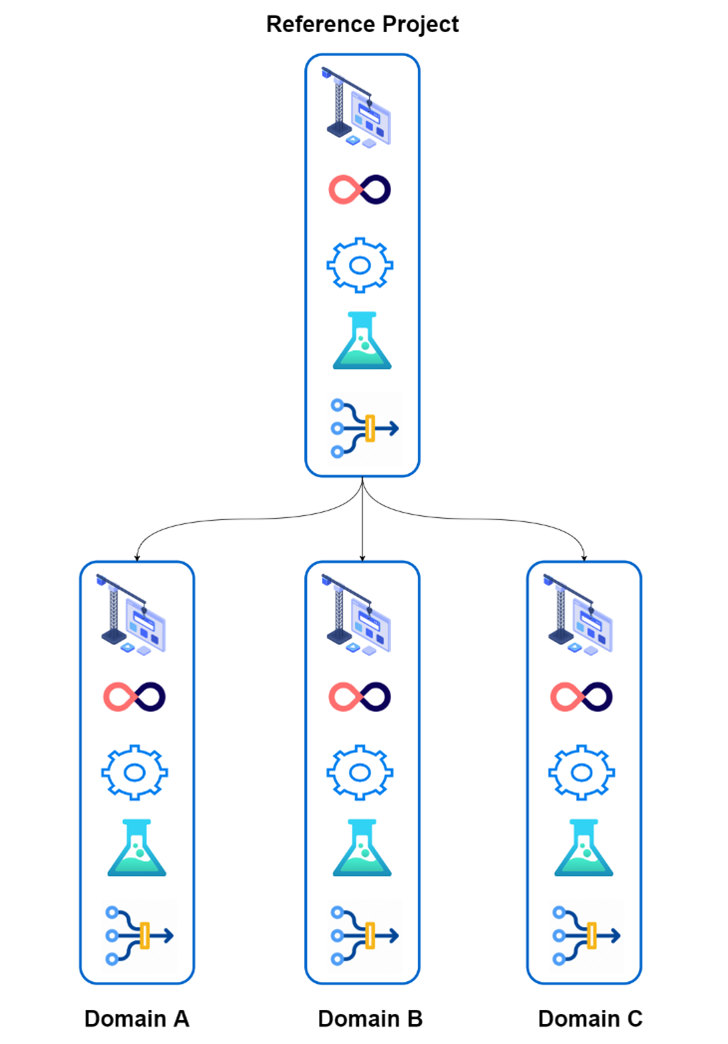
Leveraging Snowflake to Enable Decentralisation
Snowflake is a fantastic platform. It is the best enabler for DataMesh in terms of storage and compute. But Snowflake is no silver bullet.
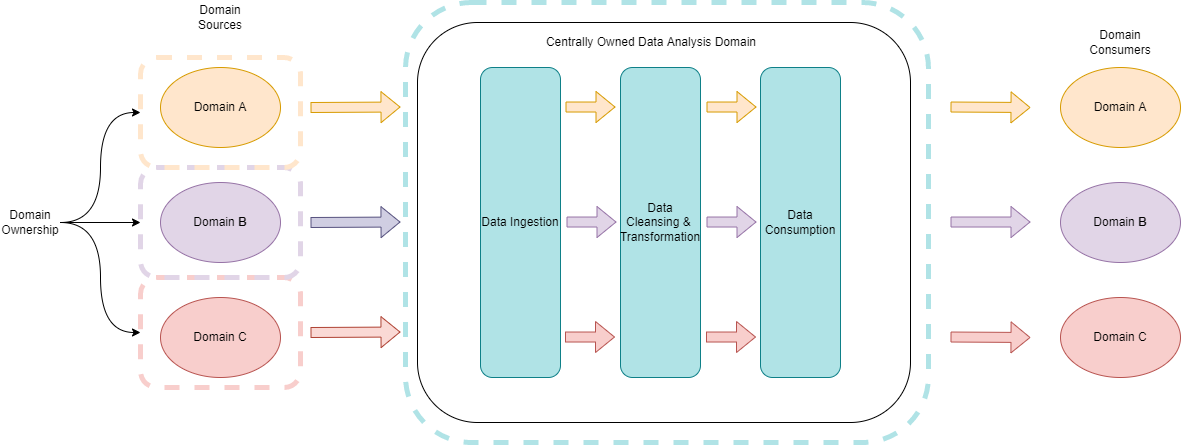
The diagram below shows a conceptual view of a data platform. It follows the centrally owned paradigm. We criticized this earlier. The domains own the operational systems. But the Data Platform Domain owns the Data Ingestions, Transformation & Modelling, and Consumption Interfaces.
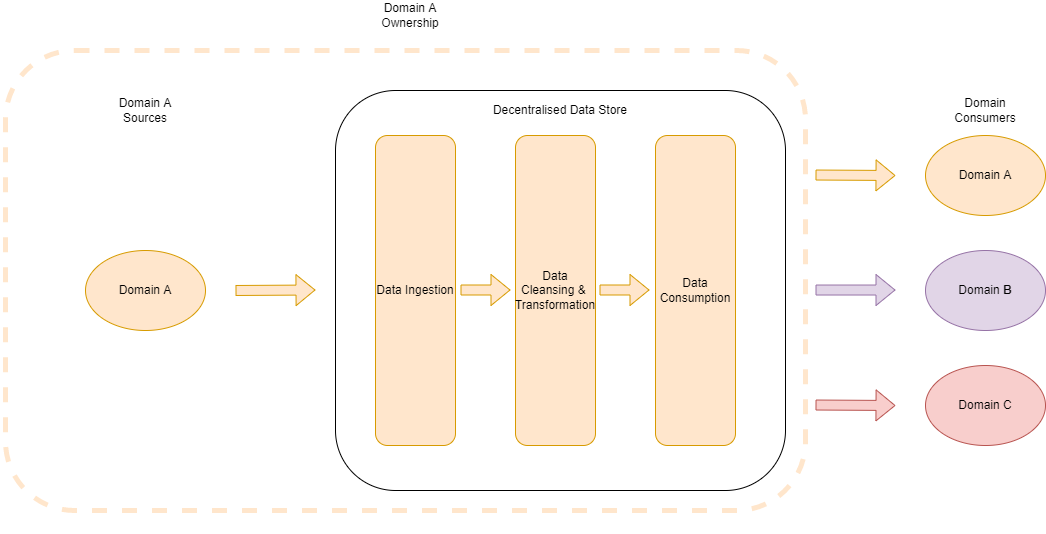
Here we have what a decentralized data architecture looks like from “Domain A’s” perspective.
All domains can use Snowflake as the data storage and compute platform. The diagram below may be more prescriptive than Zhamak’s vision. But it provides consistency for accessing and exploring other domains’ data sets.
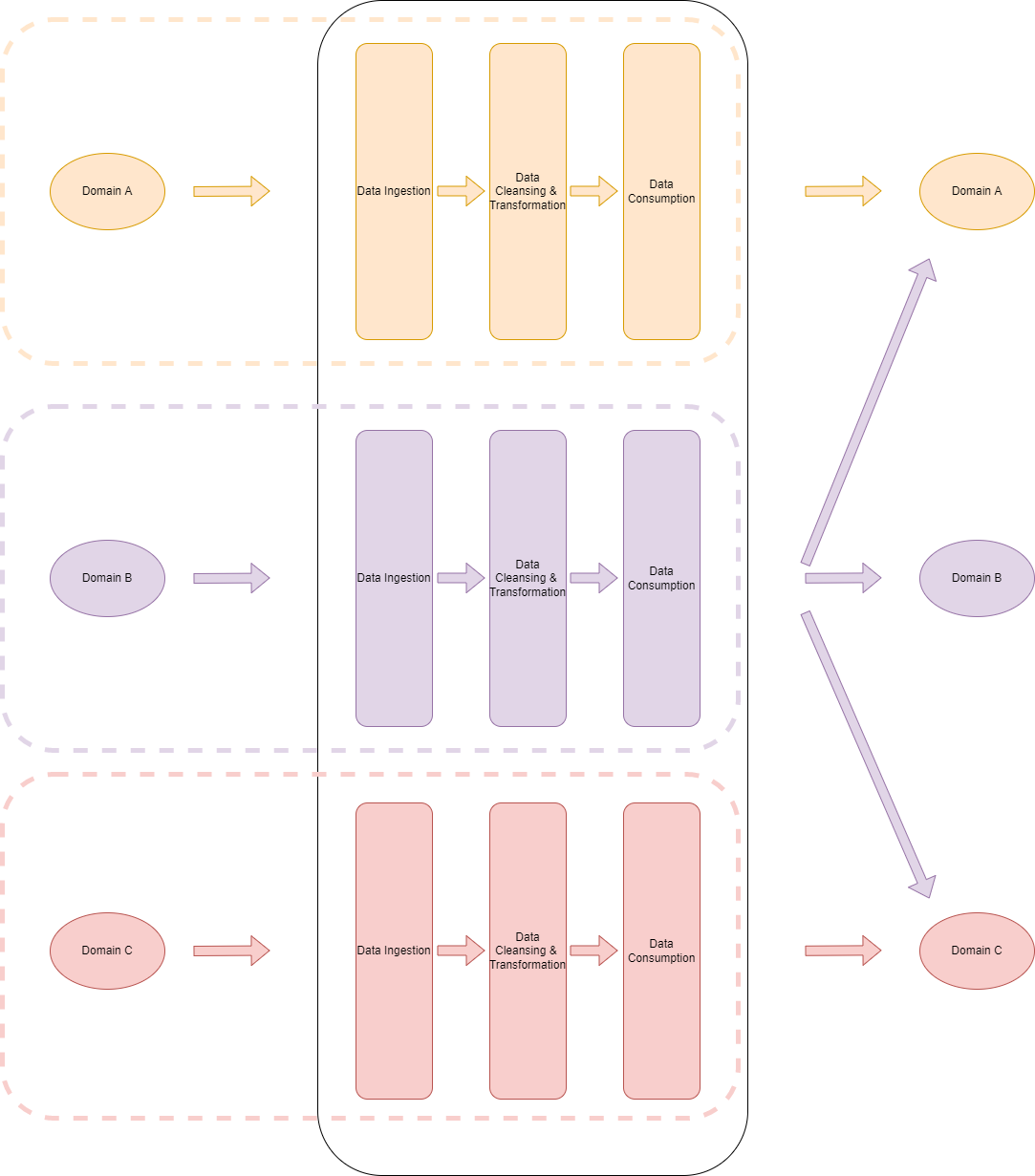
This is one of the (many) areas where DataOps for Snowflake is strong. It provides the complete framework for how to implement a DataOps pipeline. This reduces the number of global decisions to make when implementing Data Mesh.
Domains will align on HOW they implement data pipelines, infrastructure, and CI/CD. They will focus on the domain specific aspects of their data products. DataOps for Snowflake is prescriptive when it’s helpful and flexible where it’s needed.
Closing Thoughts
The aim of this blog was to reiterate and appreciate the architectural problems that were defined in Zhamak’s articles and to see if those failure modes could be addressed with a pragmatic approach. I think a combination of architectural tweaks, organizational restructuring and use of modern DataOps tooling like DataOps for Snowflake means that DataMesh can be achieved without tearing down the existing platforms and having to start from scratch (although in some cases that might be necessary too!).
I also want to acknowledge that the size, complexity and budget of an organization will play a large factor in deciding whether Data Mesh is the right pattern to follow. Perhaps a centralized bottleneck isn’t a problem that’s costly enough for some businesses to address immediately.
I hope to write more blogs to augment and finesse my views on Data Mesh in the near future, so watch this space.
👍