…and how to fix them!
We’ve asked our team of Talend experts to compile this top ten list of their biggest bugbears when it comes to jobs they see in the wild – and here it is!
10. Size does matter
Kicking off our list is a common problem – the size of individual Talend jobs. Whilst it is often convenient to contain all similar logic and data in a single job, you can soon run into problems when building or deploying a huge job, not to mention trying to debug a niggling nasty in the midst of all those
Also, big jobs often contain big sub-jobs (those blue-shaded blocks that flows form into), and you will eventually come up against a Java error telling you some code is “exceeding the 65535 bytes limit”. This is a fundamental limitation of Java that limits the size of a method’s code, and Talend generates a method for each sub-job.
Our best advice is to break down big jobs into smaller, more manageable (and testable) units, which can then be combined together using your favourite orchestration technique.
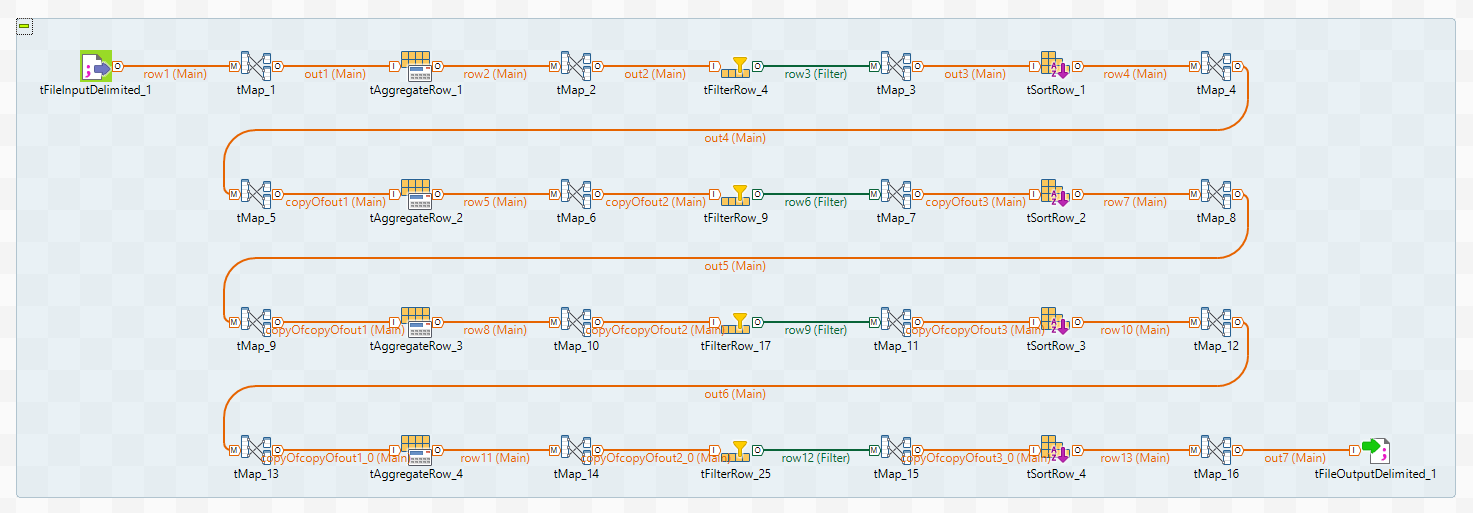
9. Joblets that take on too much responsibility
This usage will require additional complexities when reusing
We have found that you can get the best from
8. “I’m not a coder, so I’m not looking at the code”
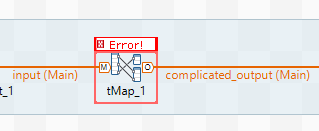
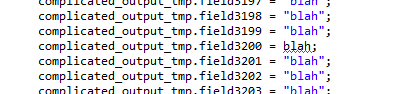
Ever seen a NullPointerException? If you’re a Talend engineer, then of course you have! However, this kind of run-time error can be tricky to pin down, especially if it lives in the heart of a busy tMap. Inexperienced Talend engineers will often spend hours picking apart a job to find the source of this kind of
If you’ve worked with Talend for a while, or if you have Java experience, you will recognise the stack trace, the nested list of exceptions that are bubbled up through the job as it falls over. You can pick out the line number of the first error in the list (sometimes it’s not the first, but it’ll be near the top), switch to the job’s code view and go to that line (ctrl-L).
Even if the resulting splodge of Java code doesn’t mean much, Eclipse (the technology that Talend Studio is built on) will helpfully point out where the problem is, and in the case of a tMap it’s then clear which mapping or variable is at fault.
7. No version of this makes sense
Talend, Git (and SVN) and Nexus all provide great methods to control, increment, freeze and roll back versions of code – so why don’t people use them! Too often we encounter a Talend project that uses just a single, master branch in source control, has all the jobs and metadata still on version 0.1 in Studio, and no clear policy on deployment to Nexus.
Without versioning, you’ll miss out on being able to clearly track changes across common artefacts, struggle to trace back through the history of part of a project, and maybe get into a pickle when rolling back deployed code.
It’s too huge a topic to go into here, but our advice is to learn how your source control system works – Git is a fantastic bit of software once you know what it can do, and come up with a workable policy for versioning projects sources and artefacts.
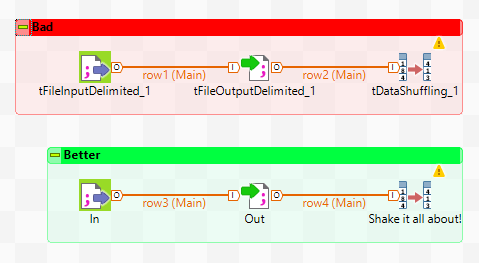
6. What’s in a name?
Whilst we’re on the topic of not having policies for things, what about naming? A busy project gets in a mess really quickly if there’s no coherent approach to the naming of jobs, context groups/variables, and other metadata items.
It can be daunting to approach the topic of naming conventions, as we’ve all seen policy documents that would put Tolstoy to shame, but it doesn’t need to be exhaustive. Just putting together a one-pager to cover the basics, and making sure all engineers can find, read and understand it, will go a long way.
Also, while you’re about it, think about routinely renaming components and flows within jobs to give them more meaningful names. Few of us would disagree that tFileInputDelimited405 is not quite as clear and informative LoadCustomerCSV, so why don’t we do it more? And renaming flows, particularly those leading into
5. Don’t touch the contexts!
So often we see context variables being updated at different points in a job – it’s so easy to do as they’re right there at context.whatever, with the right data type and everything. But then how can you refer back to the original parameter values? And what if you then want to pass the original context into a child job, or log
If you need a place to store and update variables within a job, the
4. But I like all these columns, don’t make me choose!
Something that adds to the unnecessary complexity and memory requirements of a job is all those columns that are pulled from the database or read from the file and not needed. Add to that, all the rows of data which get read from sources, only to be filtered out or discarded much later in the job, and no wonder the DevOps team keep complaining there’s no memory left on the job server!
We find that
3. Hey, lets keep all these variables, just in case
Context groups are great – just sprinkle them liberally on a job and you suddenly have access to all the variables you’ll ever need. But it can soon get to the point where, especially for smaller jobs, you find that most of them are irrelevant. There can be also cases where the purpose of certain context groups overlap leading to uncertainty about which variable should actually be set to achieve a given result.
A good approach is first to keep context groups small and focussed – limit the scope to a specific purpose, such as managing a database connection. Combine this with a clear naming convention, and you’ll reduce the risk of overlapping other sets of variables. Also, feel free to throw away variables you don’t need when adding a group to a job – if you only need to know the S3 bucket name then do away with the other variables! They can always be added back in later if needed.
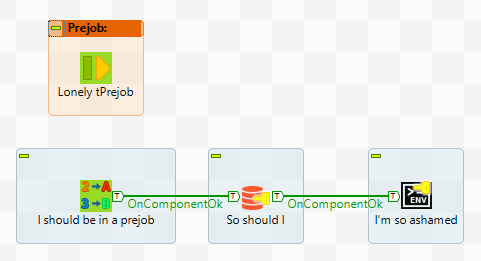
2. Jumping straight in
By missing out a tPrejob and tPostjob, you’re missing out on some simple but effective flow control and error handling. These orchestration components give developers the opportunity to specify code to run at the start and end of the job.
It could be argued that you can achieve the same effect by controlling flow with onSubjobOk triggers, but code linked to tPrejob and
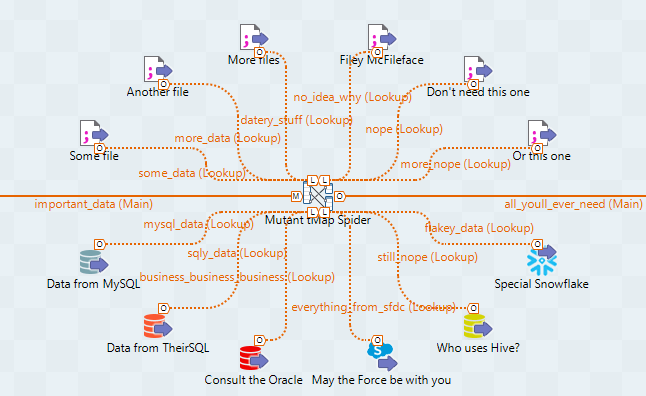
1. Mutant tMap spiders
Too many lookup inputs in a tMap, often coming in from all points of the compass, can make a Talend job look like something pulled from a shower drain. And just as nice to deal with. Add to this a multitude of variables, joins and mappings, and your humble tMap will quickly go from looking busy and important to a pile of unmanageable spaghetti.
A common solution, and one we advocate, is to enforce a separation of concerns between several serial
At the end of the day, each job, sub-job, and component should be a well-defined, well-scoped, readable, manageable and testable unit of code. That’s the dream, anyway!
Special thanks to our Talend experts Kevin, Wael, Ian, Duncan, Hemal, Andreas and Harsha for their invaluable contributions to this article.
Thank you for this article. Not only it gave me some food for thought (PreJob), some validation, it managed to do so while it also gave me some good chuckles. Of course, my fave is the mutant tMap spider.