
Introduction
Sometimes you need to merge files from a source/sources into a single file. Perhaps weekly reports into a single monthly report. Or some log files retrieved from an FTP store that you wish to aggregate together into a single file for storage or further processing. What you don’t want to do is think of the file metadata. Setting up all of the metadata will take time – especially if you have a lot of files – and if it changes at any point there is a chance that the job will break. So in this blog we are going to take a look at three different scenarios and how we can tackle them in Talend.
Scenario #1
How to read multiple files, each one with a header, and merge them together into a single file while preserving the header
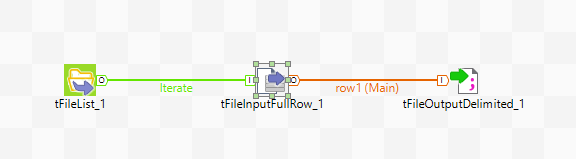
The main issue here is that ordinarily you would need to define the schema of the file first. Then you would have to make sure that the header row is added to the output. If you have numerous files and you are unsure of the metadata – meaning you don’t know if a column should be float or a double, etc – you can use the tFileInputFullRow component. The tFileInputFullRow, as the name implies, retrieves data row by row. It does not care for what columns exist and what data type they are. So in order to achieve the results that are required by the scenario we must do the following:
Add three components:
- tFileList
- tFileInputFullRow
- tFileOutputDelimited
Connect all of the components:
- tFileList to tFileInputFullRow with an “iterate” row
- tFileInputFullRow with a “main” row
Configure tFileList:
- Set the “Directory” path
- Change “Order By” method
- My scenario is using “By file name”, because the files are named in a specific format and I want to merge the data following the file naming format.
Configure tFileInputFullRow:
- Set “Fine Name” to:
((String)globalMap.get(“tFileList_1_CURRENT_FILEPATH”))
- Set “Header” to:
((Integer)globalMap.get(“tFileList_1_NB_FILE”)) > 1 ? 1 : 0
Configure tFileOutputDelimited:
- Set “File Name” to whichever output path you want
- Tick the “Append” option
That’s it. The job will now read files from the tFileList. Once it finds the files it will pass those file paths to tFileInputRow. Once tFileInputRow starts receiving the paths, it can start reading the files based on the provided path. It will not skip the header row of the first file it gets, but will skip the first row for all other files following the first. The read information is then passed to the tFileOuputDelimited file which will store the data from tFileInputFullRow wherever you have specified. The process will repeat multiple times until all of the files from tFileList are read.
Scenario #2
How to read multiple files that have no header and merge them together into a single file
Use exactly the same method as the previous Scenario #1, with only one difference: the Header option is empty for the tFileInputFullRow component.
Scenario #3
How to merge multiple files, that are using positional delimitation, into a single file while preserving the header row
The previous two methods can be applied to any flat file, however it would not work for a positional file. That is where you would need to add one extra component.
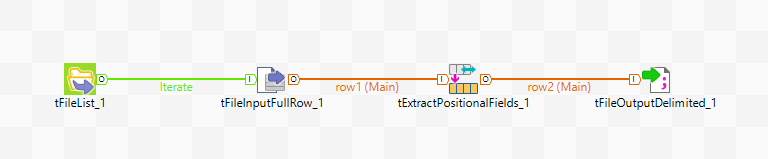
This scenario is more about making sure that the data during the mergers is kept intact, rather than making it easier for yourself by not specifying the schema. You will, after all, have to specify the amount of columns for this job to work. To create this job follow the steps below:
Add four components:
- tFileList
- tFileInputFullRow
- tExtractPositionalFields
- tFileOutputDelimited
Connect all of the components:
- tFileList to tFileInputFullRow with an “iterate” row
- tFileInputFullRow with a “main” row
Configure tFileList:
- Set the “Directory” path
- Change “Order By” method
- My scenario is using “By file name” because the files are named in a specific format and I want to merge the data following the file-naming format.
Configure tFileInputFullRow:
- Set “File Name” to:
((String)globalMap.get(“tFileList_1_CURRENT_FILEPATH”))
- Set “Header” to:
((Integer)globalMap.get(“tFileList_1_NB_FILE”)) > 1 ? 1 : 0
Configure tExtractPositionalFields:
- Set the “pattern” you expect in the files. Each column value is separated by a comma.
- Change the schema of the component accordingly, meaning for each value add a column. The names don’t matter, simply keep it as a string data type.
Note: This is what I meant when I said earlier that you need to know how many columns you expect.
Configure tFileOutputDelimited:
- Set “File Name” to whichever output path you want
- Tick the “Append” option
- If you don’t want to add a “Field Separator” and keep the data as it is, then substitute the default “;” with “”
Note: If you are going to do the last step you will need to come back to the tExtractPositionalFields, go to “Advanced setting” and tick the “Trim Column” option.
Conclusion
So, there you have it: three easy ways to merge data together without knowing the metadata of the input files. The examples that were shown are simplistic so it’s up to you to make them as sophisticated/complex as desired. For instance, you could add a tForEach component and set specific folder names within the component, which would then be passed on to the tFileList component. This in itself can than go through multiple different folder structures looking for files that need merging.
Or you can define the tFileOutputDelimited file name to a part of the tFileList current file name. For example, if you wish to merge all files with the name pattern “<SOME FILE NAME>_<YYYYMMDD>.csv” into a single file, you would remove the “<YYYYMMDD> ” part of the name. By assigning just the first part of the file name as retrieved by tFileList, you can merge multiple files of the same type into a single output.
I hope you enjoyed this blog. If you’re curious for more, why not subscribe to the Datalytyx blog to receive a monthly update of all the recently released articles?
Hi, good post. Please release other list of components like this.
Thank you.